Atlassian Jira Cloud Backup & Restore for Automated Daily Backups
The Role of Jira Cloud (Why Backup and Restore Matters)
As with any critical system data, regular backups are essential to ensure data integrity, business continuity, and disaster recovery.
This is equally true for Jira, a platform that often holds vast amounts of critical project management data. If compromised, this could lead to significant disruptions in project execution, hamper team productivity, and adversely affect overall business operations. Instances like this is where data backups come in to save the day.
Take a look at these scenarios:
- Business continuity. Jira is widely used for tracking tasks, issues, and project progress. In the event of a disaster, the organization could experience significant disruption, leading to delayed project deliveries, data loss, and potential financial impacts. Regular backups provide a reliable way to recover your data, ensuring business continuity and minimizing downtime.
- Protection against human error. Even the most meticulous users can accidentally delete tickets or make changes that impact critical data. Such deletions can have significant impacts — especially in larger projects with many stakeholders. Regular backups allow such mistakes to be easily rectified, maintaining the overall integrity of your data and ensuring the completeness of your project data.
- System updates and migrations. Implementing system changes, such as software updates or migrations to new platforms, carries inherent risk. Backups taken before such events provide a safety net, allowing you to revert to a stable state if complications arise.
- Cybersecurity resilience. In the event of cyber attacks like ransomware, where data might be encrypted or deleted, having a recent backup is crucial. It allows you to restore your data without succumbing to ransom demands or extensive data loss.
3 Things to Verify Before Initiating Your Atlassian Cloud Backup
Preparing for an Atlassian Cloud migration requires careful planning to ensure a smooth transition and mitigate the potential loss of valuable data.
Backup Frequency (RPO)
Recovery Point Objective (RPO) represents the maximum amount of data that can be lost without causing significant harm to a business.
In simpler terms, RPO answers the question: "How much data can I afford to lose before it becomes a problem?."
When considering Atlassian Cloud Backup, or any backup solution for that matter, understanding and verifying your RPO is crucial for the following reasons:
- Data Loss Tolerance. By determining your RPO, you're essentially setting a benchmark for how much recent data you can afford to lose. For instance, if your RPO is set to 24 hours, you're saying that you can tolerate a data loss of up to one day's worth of work.
- Backup Frequency. RPO directly influences how often you should be taking backups. If you have a low RPO, say 1 hour, it means you can't afford to lose more than an hour's worth of data. Consequently, you'd need to perform backups every hour to meet this objective.
- Resource Allocation. Understanding your RPO can help you allocate resources more efficiently. If you have a stringent RPO, you might need more storage, faster networks, or even dedicated backup solutions to ensure you meet that objective.
- Cost Implications. More frequent backups can lead to higher costs, both in terms of storage and the resources required to manage and monitor these backups. By setting and verifying your RPO, you can balance the trade-off between costs and the risk of data loss.
Recovery Time Objective (RTO)
While RPO (Recovery Point Objective) focuses on the amount of data you can afford to lose, RTO concentrates on the time it takes to restore that data and get your systems back online after a disruption.
In essence, RTO answers the question: "How long can my business operations be down before it becomes a significant issue?"
For instance, in terms of operational downtime, RTO sets a target for how quickly you need to restore operations after an incident. If your RTO is 4 hours, it means your goal is to have everything up and running within that time frame after a disruption.
Data Retention
Data retention refers to the policies and strategies that determine how long data backups are kept before they are either overwritten or deleted.
It's a crucial aspect of any backup strategy, as it not only ensures that you have access to historical data when needed but also helps in managing storage costs and complying with regulatory requirements.
In addition, backups can consume significant storage space over time. By setting clear data retention policies, you can manage and optimize storage usage, ensuring that you're not unnecessarily storing outdated backups.
💡Related → The 7 Best Jira Cloud Backup Providers Right Now
Atlassian Offers Exports: But It's Not Enough
While Atlassian offers some form of Jira Cloud ‘backup’ feature, the process isn’t automated nor guarantees a full recovery in the event of data loss or system failure.
For instance, Atlassian’s native cloud backup functionality only offers the XML version of your data with a limit of every 48 hours.
This means;
- You can only fully export your data once every 48 hours. So, any new data within that period is completely gone.
- You can only recover an instance, not granular data. Hence, if your developer deletes a project, issue, or attachment specific in Jira, Confluence, or JSM — there’s no recovery point.
- You have to manually copy/export your data or find a script wizard to find a way to make this easier. Manually exporting data will consume your time and managing scripts will introduce more complexity and require constant management.
What Does This Mean For Jira?
Since the native Atlassian Cloud ‘backup’ is just a mass export of data, there’s no guarantee of recovering your organization’s data in the event of data loss or accidental deletion.
Specific Limitations of Native Atlassian Backup:
- Cannot recover deleted granular data. If you accidentally delete an epic project from Jira, it cannot be retrieved in a timely manner from export.
- Spend hours/days creating backups that lack ‘granular restore’ capabilities—making it challenging and near-impossible to recover specific items or data elements.
- Are not in compliance with data retention policies. Many industries have stringent data retention policies that every organization must comply with. For example, healthcare companies in the United States must adhere to the Health Insurance Portability and Accountability Act (HIPAA), which requires them to store their data for at least seven years. Meanwhile, Atlassian Cloud deletes data after 30 days, which may not align with retention policies as the exported data may not be usable or easily accessible for the required duration.
- Are susceptible to ransomware attacks. If cybercriminals encrypt critical data within the Atlassian Cloud environment, recovering stolen data from the exported backup may be difficult due to a lack of immutable copies.
For instance, since native Atlassian backup solutions rely on Atlassian Cloud, if there’s a Supply Chain Attack that compromises any part of the platform, your data is at risk of being encrypted.
👀 Side Note → A Supply Chain Attack is a form of cyberattack targeting vulnerabilities within the supply chain of a solution.
💡Pro Tip → With HYCU, you can manage backup frequencies and retention periods. Try HYCU for free 👈
Different Native Atlassian Cloud Backup and Restore Processes
Automated Backup
Unfortunately, Atlassian does not offer an automated backup feature for Jira Cloud. You need to manually create a backup each time you want one, which can be time-consuming and may lead to inconsistent backups. Your other option is to leverage scripts and manage them yourselves.
In addition, the built-in backup functionality requires manual intervention to trigger a backup, and these backups include all data without the ability to select specific projects or issue types.
A good fix to this constant problem is to explore the third-party applications available on the Atlassian Marketplace. Several backup solutions, such as HYCU, BackUp for Jira, and others, can provide automated, scheduled backups without manual intervention.
Configuring and using backup apps for Jira Cloud
- Once you've chosen a backup solution like HYCU, you'll need to install and configure it.
- From your Jira instance, navigate to Apps > Find new apps.
- Search for HYCU, then click on Install.
- After installation, go to Apps > Manage apps, and find HYCU in the list.
- Open the app and follow the prompts to configure your backup settings. This will likely involve setting a backup schedule, choosing what data to back up, and selecting a destination for the backups.
Manual Backup
There are two ways to create a manual backup on Jira;
- Using the Jira Cloud interface to create a backup file.
- Using a script and a cron job.
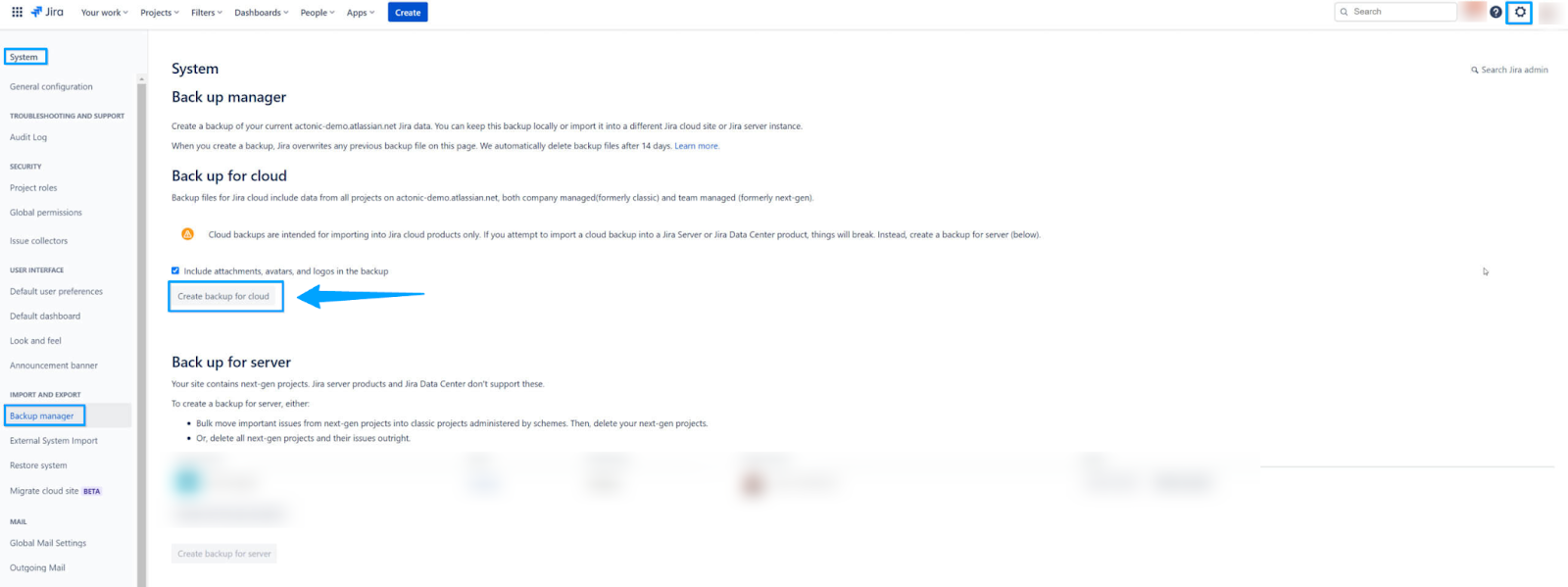
Using the Jira Cloud interface to create a backup file.
- Log in to your Jira Cloud account as an administrator.
- Navigate to the administration section.
- Click on Settings → System
- Under the “IMPORT” and “EXPORT” sections, select “Backup Manager.”
- Under “Backup for cloud,” click “Create Backup for cloud.”
- Once the backup is created, click 'Download backup' and save the backup file to your local storage.
Using a script and a cron job
Step 1. Obtain an Atlassian API key.
- Log in to your Atlassian account.
- Navigate to 'Account settings'.
- Click on 'Security', then on 'API tokens'.
- Click on 'Create API token' and give it a name.
- Copy the token to your clipboard - you will need this to authenticate your script.
Step 2. Clone the backup script repository.
- Create a custom script that uses the Atlassian API to create the backup. Alternatively, you can use a script provided by a third party.
- Use Git to clone the repository containing the script to your local machine or server.
💡Note → This script will typically use the Atlassian API key obtained in Step 1 to authenticate and access your Jira instance. The script may also include logic to manage backup files, such as deleting old backups to save storage space
Step 3. Set up a cron job
Create a cron job where your backup script is located. The cron job will define the frequency at which the backup script should run (e.g., daily, weekly, monthly, etc.)
Here’s how to do this:
- Open the crontab file for editing by running ‘crontab -e’ in your terminal.
- Add a new line in the following format:
* * * * * /path/to/script > /path/to/logfile
- The cron job will execute the backup script at the specified intervals, creating backups of your Jira Cloud instance.
- Save and close the crontab file.
Important note on cron expressions
As shown above, the five asterisks represent (in order) minute, hour, day of month, month, and day of week.
Adjust these to set the frequency of the backup. The path after the asterisks should point to your script.

A quick example is this complete cron expression: “0 0 12? * WED” - which means the trigger is set to “every Wednesday at 12:00:00 pm.”
💡 Recommended Read →More on setting cron triggers here.
Backup Scripting
Backup scripting (just as the name implies) involves writing scripts or programs to automate backing up and restoring data.
Various scripting languages can do this, but our focus is Python and Bash.
Python
Python is a high-level, interpreted programming language known for its readability and versatility.
It has a rich set of libraries and modules that can interact with APIs, handle file operations, and perform various other tasks needed in a backup and restore process. Since Python is platform-independent, it is a good choice for scripting tasks that need running on different operating systems.
Here’s an example:
Python Backup Script
import requests
API_TOKEN = 'your_api_token'
API_URL = 'https://your-instance.atlassian.net/wiki/rest/backup'
headers = {
'Accept': 'application/json',
'Authorization': f'Bearer {API_TOKEN}',
}
response = requests.post(API_URL, headers=headers)
if response.status_code == 202:
print('Backup started successfully')
else:
print(f'Failed to start backup: {response.content}')
Python Restore Script
import requests
API_TOKEN = 'your_api_token'
API_URL = 'https://your-instance.atlassian.net/wiki/rest/restore'
BACKUP_FILE_PATH = '/path/to/your/backup.tar'
headers = {
'Accept': 'application/json',
'Authorization': f'Bearer {API_TOKEN}',
}
with open(BACKUP_FILE_PATH, 'rb') as backup_file:
response = requests.post(API_URL, headers=headers, files={'file': backup_file})
if response.status_code == 202:
print('Restore started successfully')
else:
print(f'Failed to start restore: {response.content}')
Bash
Bash (Bourne Again SHell) is a command-line interpreter, or shell, for the Unix/Linux operating system.
Scripts written in Bash are typically used for file and system operations. They’re also suitable for backup scripts running in Unix/Linux systems. Also, Bash scripting can directly interact with system-level tasks, making it very powerful for backup and restore operations.
Here’s an example:
Bash Backup Script
API_TOKEN="your_api_token"
API_URL="https://your-instance.atlassian.net/wiki/rest/backup"
response=$(curl -X POST -H "Accept: application/json" -H "Authorization: Bearer $API_TOKEN" $API_URL)
if [ $? -eq 0 ]; then
echo "Backup started successfully"
else
echo "Failed to start backup: $response"
fi
Bash Restore Script
API_TOKEN="your_api_token"
API_URL="https://your-instance.atlassian.net/wiki/rest/restore"
BACKUP_FILE_PATH="/path/to/your/backup.tar"
response=$(curl -X POST -H "Accept: application/json" -H "Authorization: Bearer $API_TOKEN" -F "file=@$BACKUP_FILE_PATH" $API_URL)
if [ $? -eq 0 ]; then
echo "Restore started successfully"
else
echo "Failed to start restore: $response"
fi
💡Note → Actual API endpoints and methods may vary depending on the specific Atlassian product and the backup/restore operation type.
We recommend referring to the official Atlassian API documentation for the most accurate and up-to-date information.
Jira Cloud Backup and Restore Process
A step-by-step guide to restoring Jira Cloud data and settings:
Step 1. Prepare the backup file.
Ensure that you have a valid backup file ready for the restore process.
As mentioned earlier, this backup should be a zip file created through Jira Cloud's backup manager, a third-party tool or backup script, and a cron job.
- Verify you have all the necessary permissions and access to restore the data.
- Backup the existing data (optional but recommended)
Step 2. Initiate the restoration process
- Log in to your Jira Cloud instance as an administrator.
- Navigate to the Backup Manager by clicking Settings (the cog icon) > System > Backup Manager.
- Click 'Choose File' in the Backup Manager under the 'Restore' section.
- Locate and select your backup file.
- Click on the 'Restore' button to start the restore process. Remember, this will overwrite all existing data in your Jira Cloud instance.
💡Note → The restore process may take some time, depending on the backup size. Do not interrupt the process until it completes.
Step 3. Verify and test the restored data
- After completing the restore process, verify that your data and settings have been correctly restored. This includes issues, workflows, permissions, user data, and other settings.
You should check a sample of data across different projects to ensure all data is intact.
- Ensure that your Jira Cloud instance is working correctly.
- This could include creating and editing issues, starting and completing workflows, searching for issues, etc.
- Review the installed apps and add-ons to ensure they function correctly after the restoration.
Integrating Jira Cloud Backup with Other Atlassian Products
Atlassian’s product suite is often used together for project management (Jira Software), service management (JSM), and collaboration (Confluence).
Therefore, ensuring a consistent and reliable backup process across these tools is crucial. Here’s a look at some Atlassian products you can integrate with Jira Cloud backup.
- Jira and Confluence integration. Since Jira and Confluence often work closely together, having a consistent backup strategy for both products is beneficial. In fact, many backup apps and scripts are designed to support both Jira and Confluence simultaneously, allowing you to schedule and manage backups for both applications.
- Jira Service Management (JSM) integration. JSM is often used with Jira Software. As such, data between these two systems are tightly linked, so backups should ideally be done concurrently to ensure the data remains in sync. Also, some backup solutions specifically support Jira Service Management and can be included in your overall backup plan.
- Bitbucket integration. Bitbucket is Atlassian’s version control system, offering a few functionalities that integrate seamlessly with Jira. For instance, Atlassian provides a script-based DIY backup strategy for Bitbucket Data Center. And for the Bitbucket Cloud, you can export and import workspace data.
Meanwhile, to ensure that your backup processes are consistent across Atlassian's products:
- Synchronize your backup schedules. Try to synchronize your backup schedules so that you're backing up data from all Atlassian products at the same time. This ensures that the data across these tools is consistent and reflects the same point in time.
- Use a unified backup solution. Consider using a third-party backup solution like HYCU that supports all Atlassian products. This allows you to manage and monitor your backups from a single interface, simplifying the backup process.
💡Pro Tip → Instantly restore any Jira data (down to specific attachments, issues, and even subtasks) — all in one click!
Use Cases and Additional Functionality Provided by Backups Apps in Jira Cloud
Asides from the common automation capabilities provided by backup apps, many come with functionalities to enhance the backup and restore process, ensuring data protection and efficient disaster recovery.
Some of the additional features provided by these apps and their use cases include:
- Selective backups. Some apps allow for selective backups where you can backup specific projects or issue types instead of the entire instance. This is helpful when you only need to focus on certain projects or want to avoid overwriting specific data during a restore.
- Backup storage options. HYCU is the only solution that offers various storage options, such as local storage, cloud storage (e.g., Amazon S3, Google Cloud Storage), or dedicated backup services. This flexibility allows you to choose the most suitable storage solution based on your organization's needs.
- Data Encryption and Security. Many backup apps prioritize data security by providing encryption options for stored backup files. This ensures that sensitive data remains protected during storage and transmission.
- Backup verification. Some apps come with built-in verification mechanisms to ensure the integrity of backup files. They may perform periodic checks on backups to confirm that the data is restorable without errors.
💡Related → The 14 Best SaaS Backup Providers Right Now
Managing Backup and Restore Tasks for Multiple Jira Cloud Sites
If you manage multiple Jira Cloud sites, then efficient backup and restore management are essential. Backup apps often provide features to streamline these tasks:
- Centralized management. Use backup apps with centralized dashboards or admin interfaces to manage backup and restore tasks for multiple Jira Cloud sites from a single location.
- Bulk Operations. Opt for backup apps that perform bulk backups or restorations across multiple sites. This saves time and effort when dealing with a large number of instances.
- Consistency across sites. Backup apps help ensure consistent backup configurations and retention policies across all Jira Cloud sites, providing uniform data protection practices.
- Scheduled syncs and mirroring. In some cases, you might want to maintain synchronized backups across multiple instances. Certain backup apps provide features for scheduled syncs or mirroring to keep the backup data up-to-date across all sites.
Remember, while third-party backup apps can provide additional functionality and convenience, they also require proper setup and management to ensure your data is safely backed up and can be restored when needed.
Build vs. Buy: Jira Backups
When finding the right Jira backup solution, you’re left to choose one of two options.
- Use Atlassian’s built-in export with all its limitations — or,
- Use an advanced 3rd party solution (like HYCU) to ensure data protection and minimizing the risk of data loss in Jira Cloud
Going by what we’ve laid out in this post, opting for the Atlassian option poses more risk to the integrity and security of your backups.
For instance, you may need to restore specific projects, configurations, issues, or attachments. However, the built-in backup solution in Jira Cloud doesn't support selective restoration — it's an all-or-nothing approach. You might find yourself needing to restore the entire instance, affecting entire projects and disrupting the organization.
This makes HYCU a compelling choice for organizations that want to minimize data loss, ensure quick recovery in the face of unexpected incidents, automate their backups, and their storage offsite to AWS, Google Cloud, or Wasabi.
Backup your Jira Cloud with HYCU

- 1-click granular restore. With HYCU’s granular restore feature, you can restore specific projects, issues, configurations, and attachments with just one click based on your recovery point objectives (RPOs). This level of granularity saves you time that’ll have been spent restoring the entire backup. Plus, you get to eliminate potential data loss and improve recovery efficiency.
- Automate all backup operations in a few clicks. HYCU offers an automatic backup feature that simplifies the backup process for your Jira data. For example, with just a few clicks, you can set up the frequency and timing of your backup without requiring constant manual effort. With this, you can rest assured that you have consistent and up-to-date backups of your Jira data.
- Meet compliance requirements by storing data offsite. Storing your Jira data offsite (separate location) ensures additional protection against site-targeted attacks or accidental deletion. HYCU helps you do this by keeping backup copies of your Jira data offsite and meeting compliance requirements such as PCI, HIPAA, Sarbanes Oxley (SOX), and GDPR.
- Helps store ‘ransomware-proof’ copies of your data. To mitigate the risk of a ransomware attack encrypting or compromising your primary Jira Cloud environment, you can store immutable copies of your data in AWS, Google Cloud, or even S3 compatible storage targets like Wasabi.
💡Related → Is Data Immutability the Most Powerful Approach to Ransomware Protection?
FAQs: Jira Backups and Restore
Can I manually create a backup of my Jira Cloud data?
Yes, you can manually create a backup of your Jira Cloud data using Atlassian's built-in backup functionality. However, it does not support automated backups.
💡Related → Top 8 Small Business Backup Solutions (Cloud & On-Premises)
How often should I perform backups for my Jira data?
The frequency of your backups should depend on how often your data changes. If your data changes constantly, consider backups daily or every few hours.
How can I enable automated backups for Jira Cloud?
You can perform automated backup in Jira Cloud using third-party apps/add-ons on the Atlassian Marketplace. Alternatively, you can use a script by leveraging the Atlassian API.
How can I restore my Jira Cloud instance from a backup file?
Using Atlassian's built-in restore functionality, you can restore your Jira Cloud instance from a backup file.
What are some best practices for Jira Cloud backup strategies?
Best practices include regular backups, verifying backup files' integrity, using selective backups, automating the backup process, and storing backups securely off-site in a storage target controlled by your organization.
Can I use scripting or APIs to automate the backup process?
Yes, you can use scripting languages like Python or Bash, combined with Atlassian's APIs, to automate your backup process.
Where should I store my Jira Cloud backup files?
Backup files should be stored securely in a location outside of Atlassian.. We recommend a public cloud or S3 compatible storage target that allows for immutable copies.
We recommend following the 3-2-1 backup storage strategy.
How long should I retain my backup files?
Retaining backup files should be based on your organization's data retention policies and compliance requirements.
Can I integrate Jira Cloud backup with other Atlassian products?
Yes, many backup apps support integration with other Atlassian products like Confluence and Jira Service Management.
What backup options are available for Jira Data Center and Jira Server instances?
Below are the backup options for Jira Data Center and Jira Server instances.
- Built-in XML Backup (Jira Server and Jira Data Center)
- Jira Data Center Shared Home Directory (Data Center Only)
- Database Backup
- File System Backup
- Snapshot and Virtual Machine Backups
Which add-ons or apps should I consider in the Atlassian Marketplace for Jira Cloud backup?
HYCU is a highly recommended option for Jira Cloud backup.
- Avoid data loss and downtime. Restore anything from entire projects down to issues, subtasks, and attachments.
- Eliminate manual backups. Automate all backup operations and recover in a few clicks – no manual exports or scripting required.
- Data retention and compliance. Meet retention standards and compliance with the ability to store your data however long you need – offsite in a storage target managed by your organization.
Can I schedule backups to run automatically at specific times?
Yes, you can schedule automated backups using third-party apps or scripts. We recommend a daily backup schedule at minimum.
How can I verify the integrity of my Jira Cloud backup files?
Some backup apps provide backup verification features. Alternatively, you can perform a test restore on a non-production environment.

Andy Fernandez is the Director of Product Management at HYCU, an Atlassian Ventures company. Andy's entire career has been focused on data protection and disaster recovery for critical applications. Previously holding product and GTM positions at Zerto and Veeam, Andy’s focus now is ensuring organizations protect critical SaaS and Cloud applications across ITSM and DevOps. When not working on data protection, Andy loves attending live gigs, finding the local foodie spots, and going to the beach.