
.png)
What is AWS Backup?
Amazon Web Services (AWS) Backup is a cost-effective, fully managed, and centralized service that simplifies data backup across AWS services in the cloud and on-premises.
The system is designed to automate and consolidate all backup tasks in one place, making monitoring activity for your AWS resources easier.
Furthermore, AWS Backup is well equipped to protect storage volumes, file systems, and databases across several AWS services, including:
- Amazon DynamoDB
- Amazon Elastic Block Store (EBS)
- Amazon Relational Database Service (RDS)
- Amazon Elastic File System (EFS)
- AWS Storage Gateway
- Amazon Simple Storage Service (S3)
- Amazon Elastic Compute Cloud (EC2)
- etc.
Related Read: Top Rated Enterprise Data Backup Solutions On The Market Right Now
How AWS Backup Manages EC2 and RDS Backups
AWS Backup serves as a centralized console for managing backup operations of individual native services, including Amazon EC2 and RDS. It provides a unified interface that allows users to define backup plans, schedules, and retention policies for their EC2 instances and RDS databases.
For Amazon EC2, AWS Backup enables you to create backup plans that specify how often backups should be taken and for how long they should be retained.
Often, these plans include application-consistent backups to ensure data integrity during the backup process. Additionally, AWS Backup allows users to create Amazon Machine Images (AMIs) of their EC2 instances as part of the backup process, simplifying the restoration of instances.
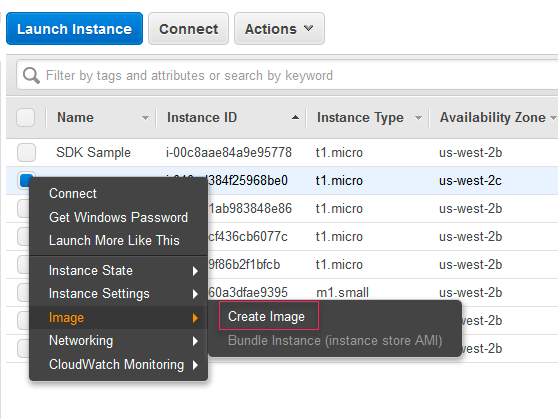
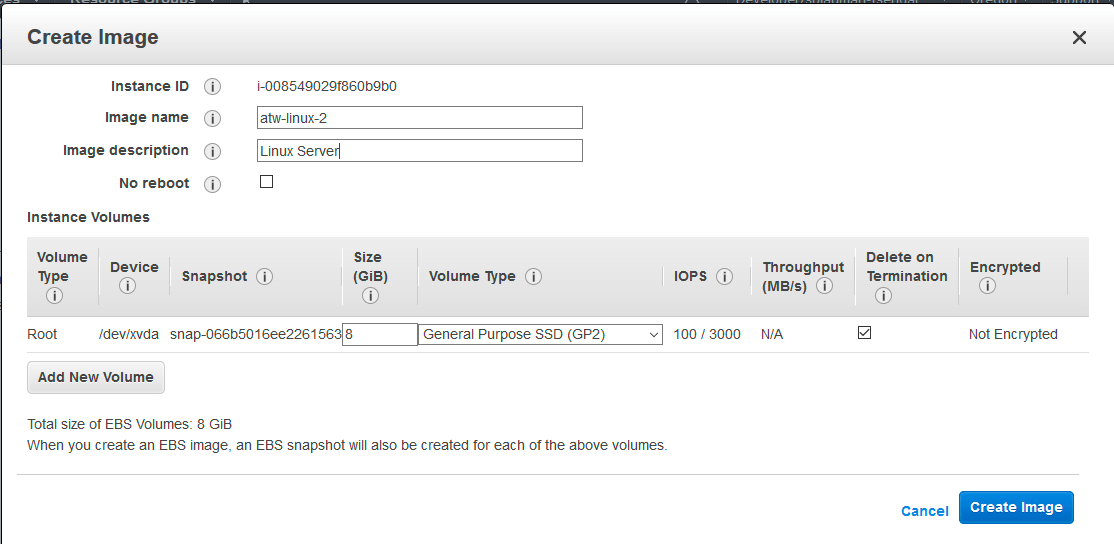

Now in the case of Amazon RDS, it automatically performs daily backups and retains them for a specified period. You can also create manual snapshots using AWS Backup, giving you more control over the backup process.
💡Note → While AWS Backup simplifies the management of EC2 and RDS backups through a centralized interface, certain aspects of the backup process may still require manual configuration and coordination with the native services.
These activities might include specifying the backup frequency, retention policies, and other parameters that vary depending on the specific use case.
How Does AWS Backup Work?
The entire ecosystem of the AWS Backup works by centralizing and automating data backup across AWS services — and to do so, it follows these steps.
Define a backup policy.
AWS Backup creates backup policies called “backup plans,” which help you define the backup requirement applicable to your AWS resource, including the backup frequency and the duration of which the backups are retained. Alternatively, you can use AWS Backup's console, API, or AWS Command Line Interface (CLI) to create and manage these policies.
For example, you can create a backup plan implementing a monthly, weekly, daily, or hourly backup schedule, depending on your needs and requirements.
In addition, you can utilize resource groups and tagging functions to categorize your backups based on specific criteria. This enables you to manage your backups more efficiently by organizing them according to your requirements.
For instance, you can choose to send older backups to cold storage, where the storage cost is lower, or set expiration policies for backups that are no longer needed [not recommended], optimizing the cost of backup storage.
Assign [preferred] AWS resources to the backup plan.
These resources can be from different AWS services, including Amazon DynamoDB tables, Amazon EBS volumes, Amazon RDS databases, Amazon EFS file systems, and AWS Storage Gateway volumes. And if you have a large number of resources, you can use the ‘resource tags’ to assign resources to a backup plan.
Initiate automatic backups.
With the backup plan created and resources assigned, AWS initiates automatic backups of the assigned resources using predefined schedules as set in the backup plan.
Move to the recovery point.
AWS stores all backup data in the ‘recovery point’ — generally referring to the different backups in AWS services. For example, Amazon Simple Storage Service (S3) is commonly used for file-level backups, while Amazon EBS is used for block-level backups. Now, each recovery point is a backup of a resource at a point in time.
Backup storage.
All AWS Backups are stored in the ‘vault to secure the backed-up data.’ These vaults are well encrypted and offer “access control” using Key Management Service (KMS).
Monitor.
After the backup, AWS Backup provides a dashboard view of backup activities across your AWS environment — but it comes with a catch.
For visibility into backup jobs, performance, consumption, and more — there are separate configurations you need to implement in order to make it happen. For example, you will need CloudTrail, CloudFormations and EventBridge as well as separate configs for notifications.
Restore.
When it’s time to restore the backed-up files, you can use AWS Backup’s restore functionality.
However, AWS does not enable-file restore for main covered services (ex. EC2). Most AWS restore options will be instance only (RDS, EC2, Aurora, etc.) There are no DB-level restores either.
But you can use the AWS Backup console, API, or CLI to initiate the restoration process. With this, you can choose specific restore points or a time to restore your data.
AWS Backup Features and Capabilities
AWS Backup offers several key features and capabilities, making it a powerful and flexible backup solution for AWS resources. Here are some of its notable features:
Cross-region Backup
AWS Backup allows you to copy backups across multiple AWS regions on demand or automatically as part of your scheduled backup plan. This is particularly useful in disaster recovery situations or as part of a compliance requirement where you must store backups far from their origin.
Cross-account backup and management
With AWS Backup, you can manage backups across all AWS accounts in your organization by automatically using their backup policies to apply backup plans.
In addition, the cross-account backup feature aids in copying backups to multiple different AWS accounts inside your AWS Organization's management structure. This means you can “fan in” and “fan out” your backups.
By fanning in, you take your backups across multiple AWS accounts and put them in a single repository account — making monitoring backup activities easier.
Then by fanning out, you take your backups and copy them to other accounts, achieving increased resilience. This provides additional protection against accidental deletion and malicious activity.
Lifecycle Management Policies
AWS Backup lifecycle management policies automatically transition backup data to a low-cost cold storage tier after a specific period. It can also be set to automatically delete backups at the end of their lifecycle, ensuring you don't pay for storage you no longer need.
Centralized Backup Management
AWS Backup provides a centralized console, API, and CLI for managing backups across multiple AWS services. It allows you to define and manage backup policies from a single location, simplifying the backup configuration and management process.
Backup Activity Monitoring and Reporting
AWS Backup integrates with AWS CloudWatch and AWS CloudTrail, providing detailed backup and restore job reporting. You can monitor the progress of your backup and restore jobs, get alerts about any potential issues, and generate compliance reports, giving you full visibility and control over your backup operations.
AWS Backup also integrates with EventBridge, which allows you to view and monitor backup events in real time through the centralized dashboard.
Backup Vault
The backup vault feature on AWS backup offers full encryption and resource-based access policies that let you control who has access to your backups — and even the vault.
Although the content of each AWS Backup backup is immutable (meaning no one can alter it), you can still use the AWS Backup Vault Lock to enforce a WORM (write-once-read-many) security model. This prevents anyone (including you) from deleting backups or altering their retention period.
Compliance and Auditing
The Backup Audit Manager on AWS Backup provides built-in controls to manage your backup activities, allowing you to meet auditing, compliance, and governance requirements.
For instance, you can run an account-based audit to help identify specific resources and activities that still need to be compliant. It also supports AWS Organizations, which allows you to manage and monitor backups across multiple accounts.
However, it comes with a catch — AWS requires separate configurations and additional services for audits. We’d recommend diving into this YouTube video for more specifics on how it all works.
Full and Incremental Backups
Full backups
When you perform a full backup, AWS Backup captures all the data in the selected resource at the point in time when the backup job is initiated. This backup is then stored as a recovery point in a backup vault. The recovery point contains all the information needed to restore the data to its state at the backup point.
One of the primary advantages of the full backup feature is that it automatically encrypts your backups with the KMS key of your AWS Backup vault. This adds an extra layer of protection to your AWS Backups.
Incremental backups
AWS Backup supports incremental backups, capturing only the changes made since the last backup. This reduces the backup duration and storage costs by avoiding redundant data copies.
Use a mix of full and incremental backups as part of a balanced backup strategy. For instance, you could perform a full backup once a week and incremental backups on other days. This approach provides comprehensive data protection while helping to manage storage costs.
These features and capabilities make AWS Backup a comprehensive solution for managing backups on AWS, ensuring your data is well-protected and helping you meet your business continuity and compliance requirements.
💡Note → AWS Backup doesn’t offer incremental backup support for DocumentDB, Neptune, Amazon Redshift, and DynamoDB.
How To Create AWS Backup for EC2 Instances
To create a backup on AWS, follow the steps outlined below.
Step 1: Create a backup plan
- Log on to the ‘AWS Management Console’ (via https://console.aws.amazon.com/) and sign in using your AWS account credentials.
- Navigate to the ‘AWS Backup Service.’
- Click on ‘Management & Governance’ — or type “backup.”
- Click “backup plans” and “Create a backup plan.”
Step 2: Configure backup plan settings
There are two ways to create a backup plan; You can choose to start with an existing plan template or create a new one.
For this guide, let's select "Build a new plan" and give it a name. Next, we configure our backup settings based on our needs.
- Choose backup frequency (e.g., Daily, hourly, or monthly).
- Choose a backup window (which is when the backup will occur).
- Specify the lifecycle rules, which determine how long your backups are retained.
- You can set retention periods based on specific criteria such as days, weeks, months, or years.
- Optionally, enable ‘cross-region backups’ to store copies of your backups in a different AWS region for added resiliency.
Step 3: Define backup rules
Navigate to the “Advanced backup settings” section and choose your backup method from the options outlined.
On the next screen, you'll be asked to assign resources.
💡Note → Assigning resources specifies which resources AWS Backup will protect using your newly created or existing backup plan.
There are three ways of assigning resources in AWS Backup;
- Assigning resources using the console.
- Assigning resources using AWS CloudInformation.
- Assigning resources programmatically.
For this guide, we’ll be assigning resources using the console.
- In the “Assign Resources” section, you'll see two options: “Assign resources by” and “Assign resources using tags.”
If you’re assigning resources manually:
- Choose “Assign resources by” and click on “Add resource.”
- In the “Resource type” dropdown, select the type of resource you want to assign. For example, if you want to assign an Amazon RDS instance, choose "RDS."
- In the “Resource ID” field, enter the resource's ID. For an RDS instance, this would be the instance identifier.
- Click on “Add” to add the resource.
You can repeat these steps to add as many resources as you want manually.
Step 4: Configure backup vault settings
- Choose the AWS Backup vault you plan to store your backup.
- Choose “Create a backup vault.”
- Provide a name for the vault and optionally add a description based on its need — e.g., if it’s for company financial records, it could be “[company_name_Financial_Records_year].”
- Choose the encryption settings for your backups. You can use AWS KMS to manage the encryption keys or let AWS Backup manage them automatically.
- Click on “Create Backup Vault.”
Step 5: Review and create a backup plan
Review all the settings — and if everything is okay, click “Create plan.”
Now, AWS Backup will automatically back up your resources according to the rules defined in the plan.
You can monitor the status of these backups by going to the “Job” section in AWS Backup. With this, you can restore data from backups, modify backup plans, and perform other backup-related tasks.
💡Please note that costs are associated with the use of AWS Backup and storage consumed by the backups.
Make sure to review the AWS pricing page for detailed cost information.
AWS Backup Best Practices
- Define Clear RTO and RPO
- Utilize Cost-Effective Storage Solutions
- Manage Versioning and Snapshot Lifecycle
- Encrypt Backup Data and Vault
- Implement a Multi-Region Disaster Recovery Plan
- Monitor and Test Your Backups Regularly
- Automate Your Backup Operations
1. Define Clear RTO and RPO
Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are two essential metrics in designing an effective backup and disaster recovery strategy. They guide decisions about backup frequency, replication, and the infrastructure needed to run your applications after a disaster.
Recovery Time Objective (RTO)
This is the maximum acceptable length of time your application can be offline. This metric determines your application's downtime in case of a failure or disaster.
For example, if your RTO is set to 2 hours, your backup and recovery strategy should be designed to restore the system within 2 hours after any failure.
Recovery Point Objective (RPO).
This is the maximum age of files that an organization must recover from backup storage for normal operations to resume after a disaster. In other words, it's the amount of data you can afford to lose.
For example, if your RPO is 1 hour, you need to back up your data at least every hour to ensure minimal data loss.
RTO and RPO in AWS Backup
When using AWS Backup, ensure to design your backup strategy to meet your required RTO and RPO.
- You can schedule backups at the frequency required to meet your RPO. For example, if your RPO is 1 hour, you might schedule backups to occur hourly.
- To meet your RTO, consider using faster restore options available in AWS. For example, you could use the provisioned capacity to ensure shorter restore times for Amazon EFS file systems.
Note, your business needs and regulatory requirements should drive these decisions. Remember, more frequent backups and longer retention periods can increase AWS storage costs, so you need to find a balance that ensures data protection and business continuity without excessive costs.
2. Utilize Cost-effective Storage Solutions
The more backups you store, the quicker your storage fills up. Over time, this accumulates, resulting in significant costs, especially for large volumes of data or when data is retained for extended periods. Optimizing these costs while ensuring your data is available when needed is important.
One of the AWS Backup capabilities you can utilize for this is its integration with various AWS storage services. This provides a range of storage options — all with different performance characteristics and price points.
Meanwhile, two policies you should take advantage of are; lifecycle management and retention policies.
Lifecycle Management
AWS Backup enables you to automatically implement lifecycle policies to transition backup data between different storage tiers. This feature can help you significantly reduce storage costs.
For example, you might initially store backup data in Amazon S3 (a higher-cost but readily accessible storage tier) and then transition it to Amazon S3 Glacier or Amazon S3 Glacier Deep Archive (lower-cost storage tiers) after a certain period.
💡Note → These “Colder” storage tiers have longer retrieval times, so this strategy best suits data you’re unlikely to need to restore immediately.
Retention Policies
You can configure AWS Backup to delete backups after a certain period. By defining retention policies, you can ensure you're not paying for storage you no longer need.
For example, you could retain daily backups for one month, weekly backups for three months, and monthly backups for a year. This policy would allow you to recover data from various points in time while controlling storage costs.
3. Manage Versioning and Snapshot Lifecycle
Versioning and snapshot lifecycle management are key aspects of maintaining proper AWS Backup. They ensure that your backups are available and retrievable for different versions of your data and that older, unnecessary backups are properly disposed of.
Versioning
Versioning involves keeping multiple versions of your backups, each representing a different point in time. This strategy allows you to restore data from any of these versions, which can be crucial if a problem such as data corruption, accidental deletion, or a ransomware attack impacts your current data.
AWS Backup provides versioning capabilities through its snapshot feature. Each time you take a snapshot of a resource, it is stored as a separate recovery point. Depending on your needs, you can choose to recover data from any of these recovery points.
Snapshot Lifecycle Management
Snapshot lifecycle management involves defining when and how your snapshots (or backup versions) should be transitioned between different storage tiers or deleted. It's an essential strategy for managing storage costs and ensuring compliance with data retention policies.
In AWS Backup, you can define lifecycle rules within your backup plan. For instance, you might define a rule to transition backups to a cheaper storage tier after 30 days and delete them after one year. This approach helps balance keeping backups for a sufficient time and avoiding unnecessary storage costs.
By managing versioning and snapshot lifecycles effectively, you can ensure that you're able to restore data from different points in time, comply with data retention policies, and optimize your backup storage costs.
4. Encrypt Backup Data and Vault
If your organization handles sensitive data, chances are, you’ll be mandated to have a robust data protection system. One way to do this is by encrypting the data and its storage, which is the vault.
One recommended practice is to take full advantage of AWS cloud protection, which helps encrypt your data in transit and at rest.
Encryption at rest
AWS Backup encrypts backup data at rest, ensuring unauthorized individuals cannot access sensitive data. Also, when you create a backup vault, you can specify an AWS Key Management Service (AWS KMS) key to encrypt backup data stored in that vault.
In addition, AWS Backup also supports customer-managed keys, giving you more flexibility and control, including key rotation, key policy configuration, and detailed usage auditing.
Alternatively, you can use AWS CloudHSM to generate and use your encryption keys. With this, you can deploy high reliability and low latency workloads and help meet regulatory compliance.
This not only helps protect your data from unauthorized access, but it's also often required to comply with data protection regulations like GDPR and HIPAA.
Encryption in transit
AWS Backup also encrypts data in transit when backing up and restoring data. This means data is protected as it moves between your resources and AWS Backup or between different parts of AWS Backup.
5. Implement a Multi-Region Disaster Recovery Plan
Enhance your disaster recovery capabilities by copying backups across multiple AWS regions.
This geographical redundancy can safeguard your data in the event of a region-specific disaster or disruptions such as natural disasters or power outages.
In addition, AWS Backup, combined with other AWS services, provides options for cross-region replication and failover.
For example, you can use services like Amazon S3 Cross-Region Replication or Amazon Aurora Global Database to automatically replicate backups across regions. In case of a regional failure, you can easily failover to the replicated backups in another region, ensuring seamless continuity of operations.
To implement multi-region backups:
- Enable cross-region backup under 'Backup settings' when creating or editing a backup plan.
- Specify the destination region for copied backups.
💡Pro Tip → You should plan and test this recovery process in advance to ensure you can meet your Recovery Time Objectives (RTOs).
6. Monitor and Test Your Backups Regularly
Even the best backup strategy can only be effective if regularly tested and monitored. Routine testing ensures that your backups can be restored when needed, while continuous monitoring helps catch potential issues before they become problems.
In terms of testing your backups, do this:
- Define a regular testing schedule to validate your backups and restoration procedures — especially when you make significant changes to your data or application.
- Conduct restoration tests to validate the recoverability of your backup data. Test different data types and scenarios, ensuring your backups can be restored and accessible when needed.
For instance, you can use AWS CloudWatch to monitor the status of your backup and restore jobs, track the storage usage of your backup vaults, and set up alarms for events like failed backup jobs.
AWS Backup also integrates with AWS CloudTrail, which captures all API calls made to AWS Backup. You can use the logs on CloudTrail to audit your backup activity and detect unusual activity, such as an unusually high number of deleted backups.
7. Automate Your Backup Operations
Automating backups is key to maintaining regular, reliable, and efficient backups. This helps reduce human error, ensure consistent backups, and save time and resources that would otherwise be used in manual backup processes.
You can do this with AWS Backup as it allows you to automate your backups by defining backup plans.
To automate backups in AWS Backup:
- From the AWS Backup console, choose ‘Backup plans.’
- Choose ‘Create backup plan.’
- Define your backup plan (either from scratch or using a template).
- Assign resources to your backup plan using resource IDs or tags.
👀 Side Tip → A backup plan is a policy that defines when and how backups are created, how long they're retained, and how they transition through different storage tiers.
Alternatively, you can utilize AWS Organizations to automate backup policies to implement, configure, manage, and govern backup activities across supported AWS resources — all by scheduling backup operations.
💡 Related Read → The 10 Best Backup as a Service Providers (BaaS)
Limitations of AWS Backup
While AWS Backup offers many powerful features and a high level of integration with AWS services, it does have certain limitations. It's important to understand these limitations to ensure it meets your specific backup and recovery needs:
- Native to AWS ecosystem. AWS Backup is designed to work within the AWS ecosystem. This means it may not support backup and recovery of resources outside AWS, such as on-premises data centers or other cloud providers. This can be a limiting factor for hybrid or multi-cloud architectures.
- No granular restore. Depending on the service, AWS Backup may not offer granular recovery options. For instance, if you're using Amazon EFS and want to recover a single file, you may have to restore the entire filesystem. This could lead to longer recovery times and higher costs for certain use cases.
- Inefficient cross-region backup. Cross-region backup in AWS Backup is controlled at the backup vault level. If you need different cross-region settings for different resources, you'll need to create multiple backup vaults, which can increase complexity.
- Limited restore capabilities. For example, it does not allow for advanced options like point-in-time recovery of databases or the restoration of systems in a specific order to meet application dependencies. To perform more complex recovery scenarios or DR drills with AWS Backup, you would need to use additional AWS services like AWS Lambda to create custom scripts or workflows. This could increase the complexity of your backup and recovery solution and require additional time and expertise to manage.
- Restore Limitations. Perhaps one of the most crucial factors to consider in any backup solution is its ability to restore data accurately and efficiently. AWS Backup provides various options for data restoration, but it also has limitations that can affect your recovery objectives. For instance, the time it takes to perform a restore operation can vary significantly based on the backup storage class and the data size. AWS does not offer SLAs (Service Level Agreements) on restore times, which could be problematic in mission-critical scenarios where downtime is not an option.
- Scripting and Configuration Complexity. AWS Backup does offer automation capabilities, but they often require scripting and manual configuration. While the platform allows for automated backups through policies, any complex backup operation involving conditional logic or integration with other services will likely necessitate scripting. This means that you or your IT team needs to possess a good understanding of AWS SDKs, APIs, and scripting languages like Python or Shell.
- Disparate Operations Across Services. AWS Backup allows you to back up resources from a variety of AWS services like EC2, RDS, and DynamoDB. However, backup operations for these services are disparate, lacking a unified approach. The backup procedure for an EC2 instance, for example, will differ considerably from that of an RDS database. This fragmentation complicates backup management, making it less straightforward to maintain a cohesive backup strategy.
- Multi-Account Management. If your organization uses multiple AWS accounts for different departments or projects, managing backups across these accounts using AWS Backup becomes a significant challenge. AWS Backup does not provide native support for multi-account backup management. While you can work around this limitation by manually aggregating backup data or employing third-party solutions, this adds complexity and cost to your backup strategy.
- Cost Management. AWS Backup does offer some cost estimation features, but these are relatively basic. The service does not provide comprehensive insights into backup costs associated with various AWS services, storage classes, or regions. This lack of visibility can make it difficult to predict costs accurately and can lead to unexpected expenses. In some instances, users have found themselves paying for backup storage that they didn’t realize was accruing, mainly due to the absence of detailed cost analytics.
- Lack of Visibility and Monitoring. Monitoring is a vital part of any backup strategy. You need to know when a backup job has completed successfully or failed so that you can take immediate corrective actions. AWS Backup’s monitoring capabilities are somewhat limited, often requiring integration with Amazon CloudWatch for more detailed metrics and alerts. This lack of an all-in-one monitoring solution means that you'll likely have to invest additional time and resources into setting up adequate monitoring and alerting mechanisms.
💡 Avoid These Limitations With HYCU for AWS

Does AWS Backup Protect My Data?
No, it does not. At least not in the way you think it does — and here’s why.
While it’s true that AWS Backup offers some form of data protection, the responsibility of managing and initiating the recovery process in the event of a disaster falls on the customer.
Although AWS provides the tools and services required to implement disaster recovery, it's up to you [the customer] to plan, implement, and test these strategies to ensure they meet their specific Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO).
This is called the “Shared Responsibility” model.
What is the AWS Backup Shared Responsibility Model?
The Shared Responsibility Model is simply AWS’s approach to cloud security. It strictly outlines the responsibilities of AWS and the customer to ensure the security and compliance of operations in the AWS cloud.
AWS Responsibilities
- AWS is responsible for protecting the infrastructure that runs all the services offered in the AWS Cloud. This infrastructure comprises the hardware, software, networking, and facilities that run AWS Cloud services.
- For AWS Backup, AWS ensures that the service is available and reliable and that the backup data stored through the service is secure and compliant with the standards outlined in the AWS Service Level Agreement (SLA).
- AWS Global Cloud Infrastructure (GCI) enables customers to build highly resilient workload architectures.
- AWS is responsible for protecting the global infrastructure that runs AWS services. They are in charge of the physical security of their data centers and the infrastructure security comprising the compute, storage, database, and networking resources.
Customer Responsibilities
Customers are responsible for managing their data, including performing backup and restore operations and configuring those operations to meet their business needs.
Specifically, in the context of AWS Backup, customers are responsible for:
- Backup and restore configuration. Customers must configure their backup policies, including defining backup frequency, retention period, and selecting the AWS resources to backup. They also need to initiate and manage restore operations as required.
- Security configuration. While AWS provides the tools, it's up to the customer to correctly configure security settings, like encryption for backup data. Customers must manage their encryption keys if they choose to use AWS Key Management Service (KMS).
- Compliance. It's the customer's responsibility to ensure that their use of AWS Backup complies with all relevant laws and regulations. This can include specific rules around data retention, data protection, data risk mitigation and data sovereignty.
- Disaster Recovery Planning. While AWS Backup supports cross-region backup, customers must set up and manage their disaster recovery strategy, including selecting appropriate regions for backup data.
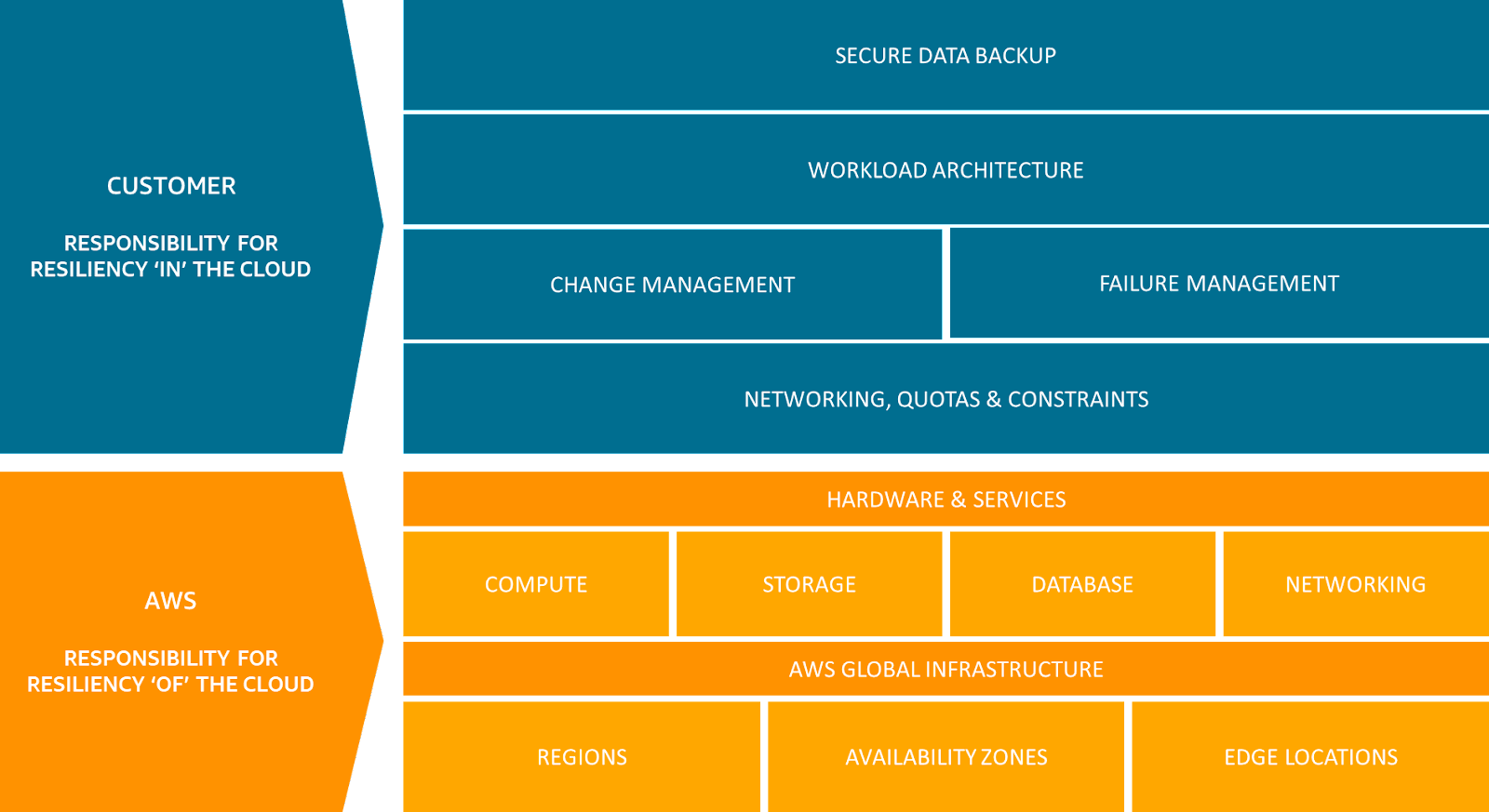
In summary, while AWS provides robust tools for backup and restore operations, the responsibility for correctly using those tools lies with you — [the customer].
As such, organizations must ensure they have the necessary expertise to manage their backup operations in AWS or consider partnering with a managed service provider to assist them.
Protect your AWS Backup with HYCU
HYCU provides application-aware data protection, data migration, and disaster recovery for AWS customers. The platform helps customers with workloads running on AWS, in the process of migrating workloads to AWS, and wants to leverage AWS as a DR target for on-prem workloads. With application-consistent backup, recovery, and migration for on-premises and public cloud environments, HYCU offers a true enterprise-class multi-cloud data protection solution.
Data Protection for AWS
HYCU offers a cloud-native solution that ensures application-consistent backup and recovery for critical workloads running on AWS.
HYCU accomplishes this through an intuitive one-click interface, seamless integration with the platform, and application-aware capabilities. Moreover, it features built-in compliance as a service on AWS.
Data Recovery for AWS
For customers seeking to utilize AWS as a disaster recovery (DR) target, HYCU offers a seamless solution to transition or 'failover' from their on-premise or public cloud workloads to AWS.
HYCU removes the necessity for upfront payments for compute resources and high-performance storage until the actual need to failover to AWS arises.
One-Click Granular Restore
One of the most significant advantages of using HYCU is its one-click granular restore feature. This functionality allows you to restore individual files, databases, or even specific database tables without having to restore the entire backup. The process is simple and straightforward, eliminating the need for any complicated scripting or configurations that are often required when using AWS Backup alone.
ZERO Scripting/Config Required
While AWS Backup often requires scripting and complex configurations for more advanced backup strategies, HYCU eliminates this requirement altogether. The platform is built to be user-friendly, allowing you to configure your backups through an intuitive graphical user interface (GUI). This means you don't need to be a scripting expert or even understand AWS SDKs to protect your data effectively. This "ZERO scripting" approach significantly reduces the learning curve and makes it easier to implement a robust backup strategy.
Set and Forget Policies
HYCU allows you to set backup policies that automatically handle all backup tasks on a predefined schedule. These set-and-forget policies are easy to configure and provide a consistent, reliable backup process. This automation not only saves time but also ensures that no backups are missed due to human error or oversight. Once configured, HYCU takes over, giving you the peace of mind that your data is being backed up according to the policy you’ve set.
Comprehensive Monitoring and Alerts
One of the limitations of AWS Backup is the lack of an all-in-one monitoring solution. HYCU fills this gap by offering comprehensive monitoring features that include notifications, reporting, and usage analytics. With HYCU, you can easily track the status of your backups, receive immediate alerts for any issues, and even generate detailed reports for auditing or compliance purposes. All of this is done through the HYCU dashboard, eliminating the need for disparate tooling or command-line interfaces.
Unified Management
HYCU provides a centralized platform for managing all your backup activities. Whether you're dealing with EC2 instances or RDS databases, HYCU offers a unified approach that makes it easy to manage backups across these services. This integrated approach eliminates the need to juggle between different tools or command-line interfaces, streamlining your backup processes and making your life significantly easier.
Why choose HYCU?

Purpose-Built for AWS
- Zero Performance impact. HYCU's deep integration with the AWS platform allows for impact-free backup and recovery by leveraging VM-level snapshots.
- Seamless AWS IAM Integration. HYCU's takes advantage of AWS Identity Access Management (IAM) for single sign-on capabilities and automatically inherits AWS security policies, enhancing efficiency.
- Integrated with AWS Billing. HYCU's as-a-service delivery for AWS synchronizes seamlessly with AWS's billing model. It is readily available for subscription directly from the AWS marketplace.
Designed with Simplicity
- Easy Deployment. With HYCU's as-a-service delivery on AWS, there's no need to expend time and resources on professional services. It instantaneously achieves the Protection-Readiness-Objective (PRO).
- No Management Hassle. As HYCU is delivered as a service, customers are spared from spending time on software maintenance and updates.
- One-Click Operations for Backup/Migration/DR. HYCU simplifies even the most complex data protection, migration, and DR workflows with its pre-set policy management.
Application-Aware Solution
- Prioritizes Applications. With HYCU's comprehensive application-consistent backup, migration, and disaster recovery, you can efficiently secure your business-critical data using VM-level snapshots.
- Lift-and-Shift. With HYCU, you can seamlessly transfer your business-critical workloads from on-premise or other public cloud providers to AWS while maintaining application consistency.
- Designed to be Agentless. HYCU's design avoids operational disruptions, requiring no agent or plugin installations or updates. This is possible due to its intelligent remote communication capabilities with AWS VMs.
Self-Service for Operational Efficiency
- Multi-Tenancy. Through AWS Resource Groups, HYCU enables secure backups in a sandbox-style environment, with quick discovery and honoring of all Resource Groups within an AWS account.
- Role-Based Access Control. Enhance organizational flexibility by delegating tasks, such as allowing database administrators to restore their databases or enabling help desk personnel to restore data for end-users.
- Equip Application Owners. By leveraging HYCU's clone and migration capabilities, organizations operating in a DevOps style can effectively manage their test and development environments.
Reduced Cost of Total Ownership
- Zero Deployment Costs. With HYCU delivered as a service on AWS, there's no need for infrastructure expenses for installation and management.
- Dynamic Scaling. HYCU allows customers to pay as they go, avoiding upfront costs for unused resources, as it can automatically scale based on the application's needs.
- Leverage Existing Infrastructure. With HYCU, there are no egress charges thanks to regional AWS object storage, and backups are highly efficient due to HYCU’s proprietary incremental-forever methodology.
Want simple, scalable data protection for AWS?



