

Was ist BigQuery?
BigQuery ist ein Data Warehouse auf Unternehmensebene mit einer serverlosen Architektur, die es den Nutzern ermöglicht, SQL-ähnliche Abfragen auf großen Datensätzen mit der Verarbeitungsleistung der Google-Infrastruktur durchzuführen.
Als vollständig verwaltete Lösung verfügt BigQuery über integrierte Funktionen wie maschinelles Lernen, Business Intelligence, Echtzeitanalysen und sogar georäumliche Analysen, die modernen Unternehmen helfen, große Datenmengen für ihre Entscheidungsfindung zu nutzen. Dies liegt vor allem an seiner Fähigkeit, Terabytes von Daten in Sekunden und Petabytes in Minuten zu verarbeiten, was es zu einem perfekten Tool für umfangreiche Datenanalysen macht.
Wichtig ist, dass BigQuery serverlos ist. Das bedeutet, dass keine Infrastrukturverwaltung erforderlich ist, was es einfacher macht, sich auf die Analyse wichtiger Daten zu konzentrieren, um aussagekräftige Erkenntnisse zu gewinnen, anstatt sich um den Overhead zu kümmern.
Bedeutung von BigQuery für die Datenanalyse und das Warehousing
Das Konzept der "Big Data" (Volumen, Geschwindigkeit und Vielfalt) stellt eine große Herausforderung für die Datenverarbeitungsmöglichkeiten herkömmlicher Systeme dar. Dies liegt gerade an ihrer begrenzten Kapazität, Skalierbarkeit und Verarbeitungsleistung, die es nahezu unmöglich und zeitaufwändig machen, sinnvolle Erkenntnisse aus riesigen und komplexen Datensätzen zu gewinnen.
Zum Glück kommt hier BigQuery ins Spiel. Die robuste Architektur von BigQuery ermöglicht es Unternehmen, Modelle für maschinelles Lernen mit strukturierten und halbstrukturierten Daten direkt in BigQuery zu erstellen, zu trainieren und bereitzustellen und so den Prozess der Gewinnung von Erkenntnissen zu rationalisieren.
Darüber hinaus nimmt BigQuery auch aufgrund seiner einzigartigen Vorteile eine wichtige Position ein, z. B:
- Ein serverloses Modell, das zur Vereinfachung von Vorgängen beiträgt.
- Dank seiner Hochgeschwindigkeitsfunktionen können Tausende von Datenzeilen pro Sekunde eingefügt werden, was Echtzeit-Analysen ermöglicht.
- Die zugrundeliegende Infrastruktur gewährleistet eine hohe Verfügbarkeit und erleichtert die automatische Skalierung zur Aufnahme großer Datenmengen.
- Es gewährleistet robuste Datensicherheit und lässt sich nahtlos mit anderen Tools und Diensten wie Data Studio, Looker und Tableau integrieren.
- SeinePay-as-you-goModell erleichtert Unternehmen die Verwaltung von Kapazitäten und Investitionskosten, insbesondere für Infrastruktur wie Server, Rechenzentren und andere Hardware.
Die Notwendigkeit von BigQuery Backup & Restore
Trotz all seiner leistungsstarken Funktionen und Möglichkeiten sind die Daten in BigQuery wie alle anderen "digitalen Daten" anfällig für versehentliches Löschen, Verlust oder Beschädigung.
Realitätsnahes Beispiel für BigQuery-Datenverlust
Nehmen wir an, ein Unternehmen nutzt BigQuery für seine Data Warehousing-Anforderungen.
- Sie speichern eine Fülle von Daten, darunter Verkaufsunterlagen, Kundeninformationen und Produktdetails.
- Eines Tages könnte ein Mitarbeiter damit beauftragt werden, veraltete Datensätze aus dem System zu löschen, um die Effizienz der Speicherung zu erhalten.
- Sie führen also einen Befehl aus, um Daten zu löschen, die älter als fünf Jahre sind.
Aufgrund eines Fehlers im SQL-Befehl interpretiert das System das Löschkriterium jedoch falsch, und alle Datensätze, die älter als ein Jahr sind, werden entfernt.
Wenn die Löschung unbemerkt bleibt und ein anderer Mitarbeiter versucht, eine mehrjährige Trendanalyse durchzuführen, wäre dies unmöglich, da ein ganzes Jahr an Daten fehlt. Ohne eine solide Sicherungsstrategie ist die Wiederherstellung dieser Daten nicht gewährleistet.
In diesem Szenario waren die Daten trotz der Zuverlässigkeit von BigQuery anfällig für menschliche Fehler - in diesem Fall versehentliches Löschen. Dies kann auch in Szenarien zutreffen, in denen es um die Einhaltung von Vorschriften und Anforderungen an die Datenaufbewahrung in einigen Unternehmen geht.
Um Ihre wertvollen Informationen zu schützen, ist es ist eine solide Sicherungsstrategie unerlässlich die sicherstellt, dass Sie sich bei unvorhergesehenen Datenproblemen schnell wiederherstellen und die Geschäftskontinuität aufrechterhalten können.
Verwendung von HYCU für Google BigQuery Backup
Wenn es um den Schutz Ihrer Daten auf Google BigQuery geht, HYCU bietet eine umfassende und einfach zu bedienende Lösung.
- Im Falle eines Datenverlusts oder Systemausfalls ermöglicht HYCU eine sofortige Wiederherstellungsfunktion, um Ihre Tabellen und vorherigen Zustände wiederherzustellen. Auf diese Weise gibt es nur minimale Ausfallzeiten und Geschäftsunterbrechungen.
- Ein weiterer Vorteil und eine besondere Stärke von HYCU ist die genaue und zuverlässige Wiederherstellungsprozess für Google Cloud. HYCU stellt sicher, dass die wiederhergestellten Daten ihre Integrität und Konsistenz beibehalten und spiegelt den Zustand der Daten zum Zeitpunkt der Sicherung wider. Dies ist besonders wichtig für analytische oder komplexe Arbeitslasten auf BigQuery, wo Datengenauigkeit und -konsistenz von größter Bedeutung sind.
Wiederherstellung von Tabellen und Datensätzen mit wenigen Klicks

Automatisieren Sie alle Backup-Vorgänge mit nur einem Mausklick
HYCU automatisiert die Sicherung Ihrer BigQuery-Datensätze, -Tabellen und -Schemata, so dass keine manuellen Eingriffe mehr erforderlich sind. Dadurch gewinnen Sie Zeit und verringern das Risiko menschlicher Fehler (z. B. versehentliches Löschen mit der Maus), die zu Datenverlusten führen können, erheblich.
Darüber hinaus bietet HYCU die Möglichkeit, die Sicherungseinstellungen anzupassen:
- Planen Sie Backups für Zeiten außerhalb der Spitzenzeiten, um die Auswirkungen auf die Leistung zu minimieren.
- Festlegung von Aufbewahrungsrichtlinien zur Einhaltung von Vorschriften.
- Wählen Sie Speicherorte für die Datensicherung, um die Datenhoheit zu gewährleisten.
Und all diese Backups werden während der Übertragung und im Ruhezustand verschlüsselt, um die Sicherheit Ihrer Daten zu gewährleisten.
Rechenfreie, native Google Cloud Backups
HYCU ist von Haus aus für die Arbeit mit Google-APIs ausgelegt, und Kunden müssen kein Skript verwenden, um Konfigurationen für herkömmliche Sicherungsvorgänge durchzuführen.
Darüber hinaus können Sie HYCU so konfigurieren, dass Ihre BigQuery-Daten auf Google Cloud Storage (GCS) für eine langfristige Datenaufbewahrung gesichert werden. Diese Flexibilität stellt sicher, dass Ihre gesicherten Daten entsprechend Ihren spezifischen Anwendungsfällen oder Anforderungen problemlos genutzt oder migriert werden können.
Über BigQuery hinaus: Schützen Sie Ihre Google Cloud Infrastruktur
HYCU bietet automatische Backups und granulare Wiederherstellung über Google Cloud Infrastruktur, DBaaS, PaaS und SaaS. HYCU bietet die umfassendste Abdeckung der Google Cloud Infrastruktur und Services mit vollständiger Unterstützung für:
- Google Cloud Motor (GCE)
- Google Cloud Storage
- Google CloudSQL
- Google BigQuery
- Google Kubernetes Engine (GKE)
- Google Cloud VMware Engine
- Google Workspace
- SAP HANA in Google Cloud
Schutz der Multi-Cloud-Infrastruktur, PaaS, DBaaS und SaaS
HYCU ist nicht nur auf die Sicherung Ihrer BigQuery-Daten beschränkt, sondern unterstützt auch verschiedene Datenquellen und Workloads. Das heißt, ob Sie andere Arbeitslasten in Google, anderen öffentlichen Clouds, lokalen Rechenzentren oder sogar SaaS-, DBaaS- und PaaS-Anwendungen haben - HYCU kann sie nahtlos sichern und wiederherstellen.
Auf der anderen Seite bietet HYCU speziell für BigQuery eine umfassende Datensicherung. Dadurch wird sichergestellt, dass alle Ihre BigQuery-Daten, einschließlich einzelner Tabellen und Schemata, wiederhergestellt werden können.
💡 Verwandte → Die 14 besten SaaS-Backup-Lösungen und -Tools für SaaS-Datenschutz
Abonnieren und schützen mit ein paar Klicks
Eines der herausragenden Merkmale von HYCU ist die benutzerfreundliche Oberfläche und die ausführliche Dokumentation, die das Einrichten und Konfigurieren Ihrer BigQuery-Backups mühelos macht.
So vereinfacht HYCU beispielsweise die Backup-Vorgänge, indem es automatisch alle Instanzen und Workloads in Ihrem Konto erkennt und es Ihnen ermöglicht, mit einem Klick vorgefertigte Richtlinien zuzuweisen oder eigene zu erstellen.
Das bedeutet, dass sie 24 Stunden am Tag, 7 Tage die Woche und 365 Tage die Woche ohne manuelle Eingriffe oder tägliche Verwaltung funktionieren.
Verbesserter Datenschutz und Sicherheit
HYCU übernimmt nicht nur automatisch die Rollen und Berechtigungen von Google Cloud IAM (Identity and Access Management), sondern bietet auch eine rollenbasierte Zugriffskontrolle (RBAC).
Mit dieser Funktion können Sie Zugriffsrechte und Rollen für Sicherungs- und Wiederherstellungsvorgänge definieren. Dies hilft, unbefugten Zugriff zu verhindern und gewährleistet, dass Ihre Datensicherungen sicher und professionell durchgeführt werden.
Diese Integration stellt sicher, dass Sicherungs- und Wiederherstellungsvorgänge nur von autorisierten Benutzern durchgeführt werden.
Kosteneffiziente Preisgestaltung
HYCU bietet flexible Preisoptionen, damit Unternehmen jeder Größe von den robusten Backup-Funktionen profitieren können. Die Kosten für die Nutzung von HYCU richten sich nach Ihren spezifischen Anforderungen, wie z. B. der Menge der zu sichernden Daten, der Häufigkeit der Backups und der erforderlichen Aufbewahrungsfrist. Auf diese Weise können Sie den Dienst an Ihre Anforderungen anpassen und zahlen nur für das, was Sie wirklich brauchen.
Ein Blick auf Ihr Google-Anwesen mit Schutzstatus
Wenn Ihr Unternehmen wie die meisten anderen ist, nutzen Sie vielleicht viel mehr Google-Dienste zusammen mit anderen öffentlichen Cloud-Diensten und SaaS-Anwendungen. Dies stellt eine große Herausforderung bei der Nachverfolgung dar, ganz zu schweigen von der Sicherstellung, dass die Daten und die Konfiguration geschützt und für die Wiederherstellung verfügbar sind. Mit R-Graph können HYCU-Benutzer die gesamte Cloud-Infrastruktur, Services, PaaS, DBaaS und SaaS in einer einzigen "Schatzkarten"-Ansicht verfolgen. Sie können verfolgen, welche Dienste geschützt und konform sind und welche geschützt werden müssen.
💡 Verwandte → Google Workspace (G Suite) Lösung zur Sicherung und Wiederherstellung
Standard-BigQuery-Sicherungsoptionen und -Konfigurationen
Um BigQuery Backup zu aktivieren, benötigen Sie Administratorzugriff mit den folgenden IAM-Rollen, um Datasets zu verwalten:
- Kopieren eines Datensatzes (Beta):
- BigQuery Admin (roles/bigquery.admin) auf dem Zielprojekt
- BigQuery Data Viewer (roles/bigquery.dataViewer) auf dem Quelldatensatz
- BigQuery Data Editor (roles/bigquery.dataEditor) auf dem Zieldatensatz
- Löschen Sie ein Dataset: BigQuery Data Owner (roles/bigquery.dataOwner) im Projekt
- Wiederherstellen eines gelöschten Datasets: BigQuery Admin (roles/bigquery.admin) auf dem Projekt
Sobald Sie Zugang haben, können Sie die unten aufgeführten Sicherungskonfigurationen und -optionen verwalten.
Kopieren von Backups auf Dataset-Ebene
Ein typisches Dataset in BigQuery ist ein Container der obersten Ebene, der Ihre Tabellen und Ansichten enthält. Es ist auch eine effektive Möglichkeit, den Zugriff auf Ihre Daten zu organisieren und zu steuern. Trennen Sie zum Beispiel Rohdaten von verarbeiteten Daten oder Daten aus verschiedenen Abteilungen oder Projekten.
Bei der Konfiguration von Backups auf Datensatzebene hingegen wird eine Kopie Ihrer Daten erstellt und an einen bestimmten Speicherort exportiert, z. B. in einen Cloud Storage Bucket. Diese Maßnahme gewährleistet die Verfügbarkeit und Integrität Ihrer Daten, selbst im Falle einer versehentlichen Löschung oder Änderung.
Methoden zur Konfiguration von Backups auf Dataset-Ebene
Es gibt zwei Methoden zur Konfiguration von Backups auf Datensatzebene: BigQuery-API und SQL-Befehle.
BigQuery-API verwenden
Mit der BigQuery-API können Sie den BigQuery Data Transfer Service verwenden, um automatische Datenübertragungen von BigQuery für einen Cloud Storage Bucket.
- Da die Backups im Bucket Google Cloud Storage gespeichert werden, erstellen Sie einen neuen Bucket unter dem Abschnitt "Storage" in der Cloud Console.
- Gehen Sie zur API-Bibliothek und aktivieren Sie die BigQuery Data Transfer Service API und Cloud Storage API.
- Wählen Sie eine Programmiersprache und installieren Sie die entsprechende Client-Bibliothek für die BigQuery-API. Lesen Sie die Dokumentation hier.
- Installieren Sie das Google Cloud SDK. Damit erhalten Sie das notwendige Befehlszeilentool für die Interaktion mit APIs und anderen Diensten von Google Cloud .
- Authentifizieren Sie das SDK mit Ihrem Google Cloud Konto, indem Sie die Befehle der gCLI verwenden. Dadurch wird sichergestellt, dass das SDK in Ihrem Namen zugreifen und Vorgänge ausführen kann.
- Wenn Sie noch keinen haben, erstellen Sie einen neuen Datensatz.
- Definieren Sie die Konfiguration. Geben Sie Dataset, Projekt, Tabellen-IDs und Cloud Storage Bucket an.
- Exportieren Sie die Daten aus Ihren BigQuery-Tabellen in einen Cloud Storage Bucket, indem Sie eine Anfrage an die API stellen.
Sobald der Vorgang bestätigt ist, stellen Sie sicher, dass sich Ihr BigQuery-Datensatz und Cloud Storage genau an der richtigen Stelle befinden, um mögliche Probleme zu vermeiden.
💡Hinweis →. Bei dieser BigQuery-Sicherungsoption handelt es sich nur um eine Kopie der vorhandenen Daten und nicht um eine inkrementelle Sicherung.
Empfohlen → Erfahren Sie mehr über Google Cloud APIs
SQL-Befehle verwenden
SQL-Befehle in BigQuery bieten eine weitere Möglichkeit zur Verwaltung und Interaktion mit Datensätzen. Im Zusammenhang mit der "Datensicherung" ist dies nicht vollständig möglich - das gilt für alle BigQuery-Sicherungsoptionen. Stattdessen wird eine neue Tabelle mit vorhandenen Daten erstellt.
Empfohlen →. Lesen Sie die Dokumentation von Google zur Erstellung von Datensätzen mit SQL-Befehlen.
💡Hinweis: Hierbei handelt es sich nicht um eine "Backup"-Lösung, sondern um die Erstellung von Datensätzen an einem anderen Ort.
Neben der Einrichtung dieser Sicherungskonfigurationen in BigQuery gibt es einige wichtige Parameter, die Sie beachten müssen:
- Häufigkeit der Sicherung. Dies hängt ganz davon ab, wie häufig sich Ihre Daten ändern. Wenn sich Ihre Daten schnell ändern, benötigen Sie möglicherweise tägliche oder stündliche Sicherungen. Wenn das nicht der Fall ist, können Sie die Häufigkeit auf monatlich oder wöchentlich einstellen.
- Aufbewahrungsrichtlinien. Diese sind nicht überall gleich und können je nach den Anforderungen Ihres Unternehmens festgelegt werden, solange sie mit den für Ihre Branche geltenden Datengesetzen übereinstimmen.
- Schema-Erhaltung. Dieser wichtige Aspekt der Konfiguration stellt sicher, dass das Schema (oder die Struktur) Ihrer Daten intakt bleibt. Das bedeutet, dass alle Datentypen, Namen, Tabellen und andere relevante Informationen auch während der Replikation korrekt sind.
Snapshots auf Tabellenebene
Die Sicherung auf Tabellenebene in BigQuery ermöglicht es Ihnen, einzelne Tabellen innerhalb eines Datasets für die Sicherung auszuwählen. Dies ist besonders nützlich in Szenarien, in denen nur einige Tabellen im Dataset gesichert werden müssen.
Erstellen von Snapshots für einzelne Tabellen.
Es gibt zwei Standardmethoden zur Erstellung von Snapshots für einzelne Tabellen;
- Sie können den 'bq extract' über das Befehlszeilentool verwenden ODER
- Sie können die BigQuery-API verwenden, um eine Anfrage zu stellen.
Hier ist ein Beispiel:
bq extract 'mein_datensatz.meine_tabelle' gs://mein_bucket/meine_tabelle_backup
Wo:
- 'my_dataset.my_table' ist die Tabelle, die Sie sichern wollen - und,
- gs://my_bucket/my_table_backup'ist der GCS-Speicherort, an dem die Sicherung gespeichert wird.
Bei beiden Methoden werden die Tabellendaten als Dateien in dem von Ihnen gewählten Format in den Google Cloud Storage (GCS) Bucket exportiert, was den Import und die Wiederherstellung der Tabelle bei Bedarf erleichtert.
Das GCS ist aufgrund seiner Sicherheit, Zuverlässigkeit und Kosteneffizienz eine bevorzugte Option für die Speicherung Ihrer BigQuery-Tabellensicherungen.
Exportieren Sie Ihre BigQuery-Tabellensicherungen in verschiedenen Formaten.
Sie können Ihre Tabellendaten in den folgenden Formaten exportieren:
- JSON (Javascript Object Notation). Dies ist ein flexibles und von Menschen lesbares Format, das leichter zu verstehen und zu bearbeiten ist. Es kann jedoch größer (in der Größe) und langsamer als andere Formate sein.
- CSV (Comma-Separated Values). Dies ist ein einfaches und weithin unterstütztes Format für die meisten Szenarien zur Darstellung von Tabellendaten. Allerdings stellt es komplexe Datenstrukturen nicht genau dar.
- Avro ist ein zeilenorientiertes Framework zur Serialisierung von Daten. Durch sein kompaktes Binärformat ist es ideal für die Verarbeitung großer Datensätze, insbesondere wenn sich das Tabellenschema im Laufe der Zeit ändert. Außerdem können Sie im Avro-Format gespeicherte Dateien komprimieren, was den Speicherplatzbedarf verringert und die Zeit für die Sicherung/Wiederherstellung verkürzt.
- Parquet (Apache Parquet) ist ein spaltenorientiertes Datenspeicherformat. Es kann auch große Datenmengen verarbeiten und bietet hervorragende Komprimierungsmöglichkeiten. Allerdings kann es bei häufigen Tabellenaktualisierungen einige Einschränkungen aufweisen.
Umgang mit partitionierten BigQuery-Tabellen und inkrementellen Backups
Die Partitionierung von Tabellen in BigQuery ist ein Ansatz zur Verwaltung und Organisation großer Datensätze.
Idealerweise sollten Sie eine Sicherung auf der Grundlage der bestehenden Partitionsstrategie durchführen.
Dazu können Sie entweder:
- die gesamte Tabelle, einschließlich aller Partitionen, sichern ODER
- oder bestimmte Partitionen zu sichern.
Der Export nur geänderter oder neu hinzugefügter Partitionen ist jedoch speichereffizienter, wenn Sie mit inkrementellen Sicherungen arbeiten.
Wenn Ihre Tabelle zum Beispiel nach Datum partitioniert ist, können Sie nur die heutige Partition extrahieren.
Beschränkungen von Snapshots auf Tabellenebene
- Ein Tabellen-Snapshot muss sich in der gleichen Region und unter der gleichen Organisation befinden wie seine Basistabelle.
- Tabellen-Snapshots sind schreibgeschützt. Sie können die Daten in einem Tabellen-Snapshot nicht aktualisieren, es sei denn, Sie erstellen eine Standardtabelle aus dem Snapshot und aktualisieren dann die Daten. Sie können nur die Metadaten eines Tabellen-Snapshots aktualisieren, z. B. seine Beschreibung, das Ablaufdatum und die Zugriffsrichtlinie.
- Aufgrund der Sieben-Tage-Grenze für Zeitreisen können Sie nur einen Schnappschuss der Daten einer Tabelle machen, wie sie vor sieben Tagen oder später waren.
- Sie können keinen Schnappschuss von einer Ansicht oder einer materialisierten Ansicht machen.
- Sie können keinen Schnappschuss von einer externen Tabelle machen.
- Sie können eine vorhandene Tabelle oder einen Tabellen-Snapshot nicht überschreiben, wenn Sie einen Tabellen-Snapshot erstellen.
- Wenn Sie einen Snapshot einer Tabelle erstellen, die Daten im schreiboptimierten Speicher (Streaming-Puffer) enthält, werden die Daten im schreiboptimierten Speicher nicht in den Tabellen-Snapshot aufgenommen.
- Wenn Sie einen Snapshot einer Tabelle erstellen, die Daten in der Zeitreise enthält, werden die Daten in der Zeitreise nicht in den Tabellen-Snapshot aufgenommen.
- Wenn Sie einen Snapshot einer partitionierten Tabelle erstellen, für die ein Partitionsablaufdatum festgelegt wurde, werden die Informationen zum Ablaufdatum der Partition nicht im Snapshot beibehalten. Die 'ge-Snapshot'-Tabelle verwendet stattdessen die Standard-Partitionsgültigkeitsdauer des Zieldatensatzes. Um die Partitionsverfallsinformationen beizubehalten, kopieren Sie die Tabelle stattdessen.
- Sie können einen Tabellen-Snapshot nicht kopieren.
Snapshot-basierte Backups
Ein Snapshot in BigQuery ist eine zeitpunktgenaue Kopie der Daten einer Tabelle (der sogenannten Basistabelle). Das bedeutet, dass der Zustand der Tabelle und ihrer Daten zu einem bestimmten Zeitpunkt erfasst wird, so dass Sie bei Bedarf von diesem Punkt aus wiederherstellen können.
Einfach ausgedrückt: Sie machen sich ein Bild von Ihren Daten. Und das kann in Fällen wie der Einhaltung von Vorschriften, der Rechnungsprüfung oder der Trendanalyse wertvoll sein, da es einen konsistenten Überblick über die Daten zu einem bestimmten Zeitpunkt bietet.
💡Hinweis →. Tabellen-Snapshots sind "schreibgeschützt", aber Sie können eine Standardtabelle aus einem Snapshot erstellen/wiederherstellen und sie dann ändern.
Erstellen und Verwalten von Snapshots für Point-in-Time-Recovery
Sie können einen Snapshot einer Tabelle mit den folgenden Optionen erstellen:
- Google Cloud Konsole
- SQL-Anweisung
- Der Befehl bq cp --snapshot
- jobs.insert API
Wenn Sie z. B. die Google Cloud Konsole verwenden, gehen Sie wie folgt vor:
- Rufen Sie die Cloud-Konsole auf, und navigieren Sie zur BigQuery-Seite.
- Finden Sie den 'Explorerund erweitern Sie die Projekt- und Dataset-Knoten der Tabelle, die Sie mit einem Snapshot versehen möchten.
- Klicken Sie auf den Namen der Tabelle, und klicken Sie auf 'SNAPSHOT.'

- Als Nächstes wird ein "Tabellen-Snapshot erstellen" angezeigt. Geben Sie das Projekt, Tabelle und ein. Datensatz Informationen für den neuen Tabellen-Snapshot.
- Stellen Sie Ihre Verfallszeit.
- Klicken Sie auf . Speichern.
Sobald Sie diesen Snapshot erstellen, wird er von der Originaltabelle getrennt. Das bedeutet, dass sich alle Änderungen an der Tabelle nicht auf die Daten des Schnappschusses in der neuen Tabelle auswirken.
Empfohlen →. Erfahren Sie mehr über die Erstellung von Tabellen-Snapshots mit anderen Optionen.
Vorteile von Snapshot-basierten Backups
- Datenversionierung. Damit können Sie auf Daten zugreifen, wie sie zu bestimmten Zeitpunkten vorlagen. Auf diese Weise können Sie Änderungen zurückverfolgen oder Daten bei Bedarf in ihren ursprünglichen Zustand zurückversetzen.
- Historische Analyse. Sie können verschiedene Snapshots vergleichen, um Datenänderungen im Laufe der Zeit zu verfolgen. Dies kann Ihnen helfen, Einblicke in Trends zu gewinnen und Ihren Entscheidungsprozess zu verbessern.
- Datenaufbewahrung. In einigen Branchen und Organisationen gelten strenge Richtlinien für die Datenaufbewahrung, um gesetzliche Vorschriften zu erfüllen. Snapshot-basierte Backups ermöglichen es Ihnen, Daten für eine bestimmte Dauer aufzubewahren, wie es die Vorschriften vorschreiben.
Nutzung der BigQuery-Zeitreisefunktion für die Wiederherstellung von Daten
BigQuery bietet eine Funktion namens "Zeitreise", mit der Sie auf die historischen Versionen Ihrer Tabelle in den letzten sieben Tagen zugreifen können.
Mit der Zeitreisefunktion können Sie die Daten einer Tabelle ab einem bestimmten Zeitpunkt wiederherstellen oder bewahren, wobei alle Änderungen, die nach diesem Zeitpunkt vorgenommen wurden, rückgängig gemacht werden.
Snapshot-basierte Backups und die Zeitreisefunktion unterstützen Ihre Datensicherungsstrategie in BigQuery erheblich.
Beachten Sie, dass "Zeitreisen" keine garantierte Lösung für die Wiederherstellung im Falle eines Betriebsausfalls, eines Cyberangriffs oder einer Naturkatastrophe sind.
Hier ist der Grund dafür:
- Das Zeitfenster für die Wiederherstellung von Daten ist auf sieben Tage begrenzt. Bleibt ein Problem innerhalb dieses Zeitraums unentdeckt, können die Daten nicht wiederhergestellt werden.
- Zeitreisen bieten nicht die Möglichkeit, Ihre Daten zu duplizieren oder zu sichern. Sie ermöglicht es Ihnen lediglich, zu den vorherigen Zuständen Ihrer Daten zurückzukehren.
Aus diesem Grund ist es von entscheidender Bedeutung, andere Sicherungsmaßnahmen wie regelmäßige Datenexporte auf Google Cloud Storage und Datenreplikation einzusetzen, um eine umfassende Datensicherheit zu gewährleisten.
Implementieren von BigQuery-Backup-Lösungen
Verwendung von Python und GitHub
Mit seiner benutzerfreundlichen und umfangreichen Bibliotheksunterstützung erleichtert Python die Interaktion mit BigQuery und automatisiert den gesamten Sicherungsprozess.
Mit Python und GitHub, einer führenden Plattform für das Hosting und die Versionskontrolle von Code, können Sie jetzt Ihre Skripte verwalten, Änderungen verfolgen und sogar mit anderen zusammenarbeiten.
Damit dies funktioniert, müssen Sie vorhandene Python-Bibliotheken und -Repositories nutzen, um Ihren Entwicklungsprozess zu rationalisieren:
- google-cloud-bigquery. Diese offizielle Python-Bibliothek stammt von Google Cloud und bietet Funktionen wie die Verwaltung von Datensätzen, Zeitplanung und Ausführung von Abfragen.
Hier ein Beispiel für die Verwendung von Python zur Durchführung einer Abfrage
from google.cloud import bigquery
client = bigquery.Client()
# Eine Abfrage durchführen.
QUERY = (
SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '
WHERE state = "TX" '
'LIMIT 100')
query_job = client.query(QUERY) # API-Anfrage
rows = query_job.result() # Wartet, bis die Abfrage beendet ist
for row in rows:
print(zeilen.name)
- google-cloud-storage. Diese Bibliothek macht es bequem, die Speicherung Ihrer Backups in Google Cloud zu automatisieren.
- pandas-gbq. Diese Bibliothek überbrückt die Lücke zwischen BigQuery und Pandas. Sie vereinfacht das Abrufen von Ergebnissen aus BigQuery-Tabellen durch SQL-ähnliche Abfragen.
Beispiele dafür, was man mit der pandas-gbq-Bibliothek machen kann:
Durchführen einer Abfrage:
- importieren Sie pandas_gbq
- result_dataframe = pandas_gbq.read_gbq("SELECT column FROM dataset.table WHERE value = 'something'")
Hochladen eines Datenrahmens:
- importieren Sie pandas_gbq
- pandas_gbq.to_gbq(dataframe, "dataset.table")
Darüber hinaus ist die Einhaltung einiger standardmäßiger Best Practices bei der Verwendung von Python und GitHub zur Erstellung von BigQuery-Backups entscheidend.
- Überwachen Sie Ihre Sicherungsaufträge. Implementieren Sie eine Fehlerbehandlung und -protokollierung in Ihre Skripte, um ein Warnsystem auszulösen, das Sie über mögliche Probleme mit dem Sicherungsprozess informiert.
- Modularisieren Sie Ihre Python-Skripte. Modularisierung ist einfach eine Möglichkeit, Programme zu organisieren, wenn sie komplizierter werden. In diesem Fall sollten Sie Ihre Funktionen für die Datensicherung in wiederverwendbare Modelle aufteilen, damit sie bei wachsendem Umfang leichter zu verwalten und zu pflegen sind.
- Verwenden Sie Konfigurationsdateien. Diese werden auch als "Konfigurationsdateien" bezeichnetunddienen zum Speichern von Schlüssel-Wert-Paaren eines Python-Codes. Wenn Sie beispielsweise BigQuery-Sicherungen durchführen, können Sie eine Konfigurationsdatei verwenden, um Projekt-IDs, Datensatznamen und Sicherungsorte zu speichern. Dies ermöglicht eine einfache Änderung, ohne den Code zu manipulieren.
Verwendung der Befehlszeile und Google Cloud SDK
Die Befehlszeile (oder gCLI) ist eine Reihe von Tools zur Verwaltung von Anwendungen und Ressourcen, die auf Google Cloud gehostet werden. Zu diesen Tools gehören gcloud, gsutil und bq Befehlszeilen-Tools. Sie können zum Beispiel alle Backup-Aufgaben über die Befehlszeile planen und automatisieren.
Andererseits erleichtert das Google Cloud SDK die Entwicklung und Interaktion mit der Google Cloud API in der von Ihnen bevorzugten Programmiersprache.
Kombinieren Sie beides, und Sie können Ihre BigQuery-Backups bequem verwalten.
Wie Sie Ihr Google Cloud SDK einrichten.
- Weiter zu Cloud SDK - Bibliotheken und Befehlszeilen-Tools | Google Cloud.
- Laden Sie das Installationspaket für Ihren jeweiligen Rechner (Windows, macOS, Ubuntu und Linux) herunter und folgen Sie den Anweisungen auf der Seite.
- Installieren Sie das Google Cloud SDK mit der Datei "./google-cloud-sdk/install.sh" und folgen Sie den Anweisungen.
- Authentifizieren Sie Ihr Konto, um BigQuery-Ressourcen zu aktivieren, indem Sie die Befehlszeile "gcloud auth login" verwenden.
Nachdem Sie Ihr Google Cloud SDK eingerichtet haben, können Sie als Nächstes die Befehlszeile verwenden, um verschiedene Sicherungsfunktionen auszuführen.
Erstellen von Sicherungskopien
Das Erstellen einer BigQuery-Sicherung mit der Befehlszeile '[bq cp]' bedeutet einfach, dass die Tabelle von einem Speicherort zu einem anderen kopiert wird. Die Speicherorte können sich über verschiedene Projekte, verschiedene Datensätze oder sogar innerhalb desselben Datensatzes erstrecken.
bq cp [project_id]:[dataset].[table] [project_id]:[backup_dataset].[backup_table]
Wo Ihr;
- '[project_id]' ist Ihre Google Cloud id.
- '[Dataset]' enthält die Tabelle, die Sie sichern wollen.
- '[Tabelle]' enthält den Namen der Tabelle, die Sie sichern wollen.
- '[backup_dataset]' ist das Dataset, in dem Sie die Sicherung speichern möchten.
- '[backup_table]' ist der Name der Sicherungstabelle.
Daten exportieren
Mit der Befehlszeile '[bq extract]' können Sie Daten aus BigQuery in Google Cloud Storage oder externe Speichersysteme exportieren. Diese Befehlszeile ermöglicht auch den Datenexport in JSON, CSV, Avro und Parquet.
bq extract --destination_format=[format] [project_id]:[dataset].[table] gs://[bucket]/[path]
Hier ersetzen;
- '[Format]' mit Ihrem gewünschten Exportformat.
- '[Bucket]' mit dem Namen Ihres Google Cloud Speicher-Buckets.
- '[Pfad]' mit dem Pfad, unter dem Sie die exportierten Daten speichern möchten.
Zum Beispiel:
bq extract --destination_format CSV 'mydataset.mytable' gs://mybucket/mydata.csv
Verwalten von Backups
Um Ihre BigQuery-Backups zu verwalten, verwenden Sie den Befehl '[bq ls]', um alle Backups [oder Tabellen] in einem bestimmten Dataset aufzulisten - oder '[bq rm]', um eine Tabelle zu löschen.
- bq ls mydataset
- bq rm 'meindatensatz.meinetabelle'
Beschränkungen der BigQuery-Sicherungsoptionen
Begrenzte Point-in-Time-Wiederherstellungsoption
Angenommen, Sie haben einen wichtigen Datensatz in BigQuery, der häufig aktualisiert und transformiert wird. Eines Tages wird der Datensatz aufgrund eines Datenbeschädigungsproblems ungenau.
Da BigQuery keine Point-in-Time-Wiederherstellung bietet, können Sie den Datensatz nicht einfach in einen Zustand vor der Beschädigung zurückversetzen. Ohne automatisierte Backups müssen Sie sich möglicherweise auf manuelle Exporte oder Snapshots verlassen, die Sie zuvor erstellt haben, was zeitaufwändig und möglicherweise veraltet sein kann.
Komplexer Import- und Exportprozess
Angenommen, Sie haben einen großen Datensatz in BigQuery und möchten ein Backup in einem externen Speichersystem wie Google Cloud Storage (GCS) erstellen. BigQuery ermöglicht zwar den Export von Daten in Formaten wie Avro, Parquet oder CSV, aber der Export großer Datensätze kann komplex und ressourcenintensiv sein.
So kann der Export mehrerer Terabyte an Daten in das GCS erhebliche Zeit und Netzwerkressourcen in Anspruch nehmen, was zu zusätzlichen Kosten und potenziellen Unterbrechungen des laufenden Betriebs führt.
Schlechte Aufbewahrungsrichtlinien für Backups
Standardmäßig bewahrt BigQuery gelöschte Tabellen oder Datensätze 30 Tage lang im "Papierkorb" auf, bevor sie endgültig gelöscht werden. Dies bietet zwar einen gewissen Schutz gegen versehentliches Löschen, aber Sie können diesen Aufbewahrungszeitraum nicht verlängern oder anpassen.
Ressourcenintensive Skripterstellung und Konfiguration
Die Verwaltung von Skripten und benutzerdefinierten Konfigurationen kann komplex sein, insbesondere wenn die Umgebung skaliert wird. Die Verwaltung von Skripten kann für einen Dienst wie BigQuery entmutigend und zeitintensiv sein, ganz zu schweigen davon, wenn Sie für die Verwaltung mehrerer Cloud-Dienste verantwortlich sind.
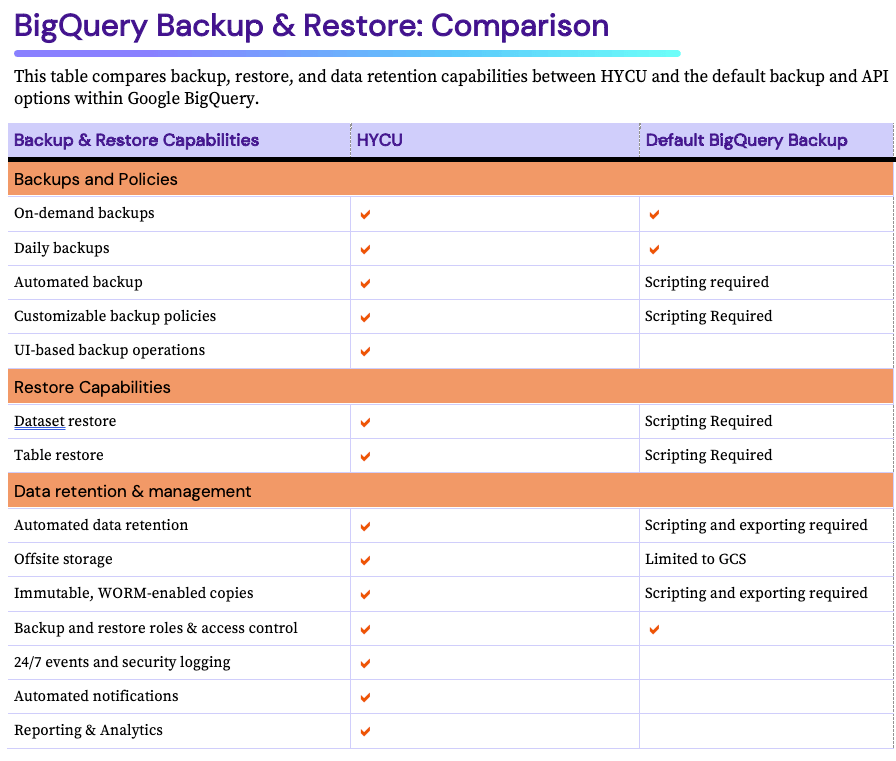
BigQuery-Sicherung und -Wiederherstellung: Die Quintessenz
Google BigQuery ist zweifellos ein leistungsstarkes Tool für datengesteuerte Unternehmen. Die blitzschnellen SQL-Abfragen, die integrierten Funktionen für maschinelles Lernen und die skalierbare Infrastruktur machen es zu einer zuverlässigen Lösung - insbesondere für die Verarbeitung großer Datenmengen. Allerdings müssen die wertvollen Schemata, Datensätze und Tabellen in BigQuery geschützt werden, um das Risiko von Datenverlusten oder Systemausfällen zu mindern. Hier kommt HYCU ins Spiel, um den Tag zu retten.
Mit HYCU Protégé erhalten Sie 1-Klick-Backups und granulare Wiederherstellung für Ihre BigQuery-Daten. Dieses automatisierte "Set and Forget"-Backup läuft 24/7/365 und bietet Ihnen die Gewissheit, dass Ihre BigQuery-Daten bei Bedarf verfügbar sind.
Benötigen Sie eine Cloud-native Sicherung und Wiederherstellung für Google BigQuery?
Schließen Sie sich den über 4200 Kunden an, die HYCU vertrauen. 👈



