BigQuery Backup & Disaster Recovery (Automated Granular Restore)
What is BigQuery?
BigQuery is an enterprise-level data warehouse with a serverless architecture that enables users to run SQL-like queries on large datasets using the processing power of Google’s infrastructure.
As a fully-managed solution, BigQuery has built-in features like machine learning, business intelligence, real-time analytics, and even geo-spatial analysis that aid modern businesses looking to leverage vast amounts of data in their decision-making process. This is particularly due to its capability of running terabytes of data in seconds and petabytes in minutes, making it a perfect tool for large-scale data analytics.
Importantly, BigQuery is serverless. Meaning there’s zero infrastructure management needed, making it easier to focus on analyzing important data to gain meaningful insights instead of worrying about overheads.
Importance of BigQuery in Data Analytics and Warehousing
The concept of ‘big data’ (volume, velocity, and variety) poses a significant challenge to the data-processing capabilities of traditional systems. This is precisely due to their limited capacity, scalability, and processing power, making extracting meaningful insights from vast and complex datasets nearly impossible and time-consuming.
Fortunately, here’s where BigQuery comes into play. BigQuery's robust architecture empowers businesses to create, train, and deploy machine learning models using structured and semi-structured data right in BigQuery, streamlining the process of extracting insights.
In addition, BigQuery also holds a vital position due to its unique advantages, such as:
- A serverless model that aids in simplifying operations.
- Its high-speed capabilities make it possible to insert thousands of rows of data per second, allowing for real-time analytics.
- Its underlying infrastructure ensures high availability, making it easy to automatically scale to accommodate large datasets.
- It ensures robust data security and integrates seamlessly with other tools and services like Data Studio, Looker, and Tableau.
- Its ‘pay-as-you-go’ model also makes it easy for businesses to manage capacity and CAPEX costs — especially on infrastructure, such as servers, data centers, and other hardware.
The Need for BigQuery Backup & Restore
Despite all its powerful features and capabilities, data in BigQuery, like any other ‘digital data,’ is vulnerable to accidental deletion, loss, or corruption.
Real-World Example of BigQuery Data Loss
Let’s say a company utilizes BigQuery for its data warehousing needs.
- They store a plethora of data, including sales records, customer information, and product details.
- One day, an employee may be tasked with clearing outdated records from the system to maintain storage efficiency.
- So they execute a command, intending to remove data older than five years.
However, due to an error in the SQL command, the system misinterprets the deletion criterion, and all records older than a year are removed.
If the deletion goes unnoticed, and another employee attempts to perform a multi-year trend analysis, it’d be impossible because a whole year of data is missing. Without a robust backup strategy in place, the recovery of this data is not guaranteed.
In this scenario, despite BigQuery’s reliability, the data within it was vulnerable to human error — accidental deletion in this case. This can also be applicable in scenarios involving regulatory compliance and data retention requirements for some organizations.
To safeguard your valuable information, it's crucial to have a robust backup strategy that ensures that you can quickly recover from any unforeseen data-related issues and maintain business continuity.
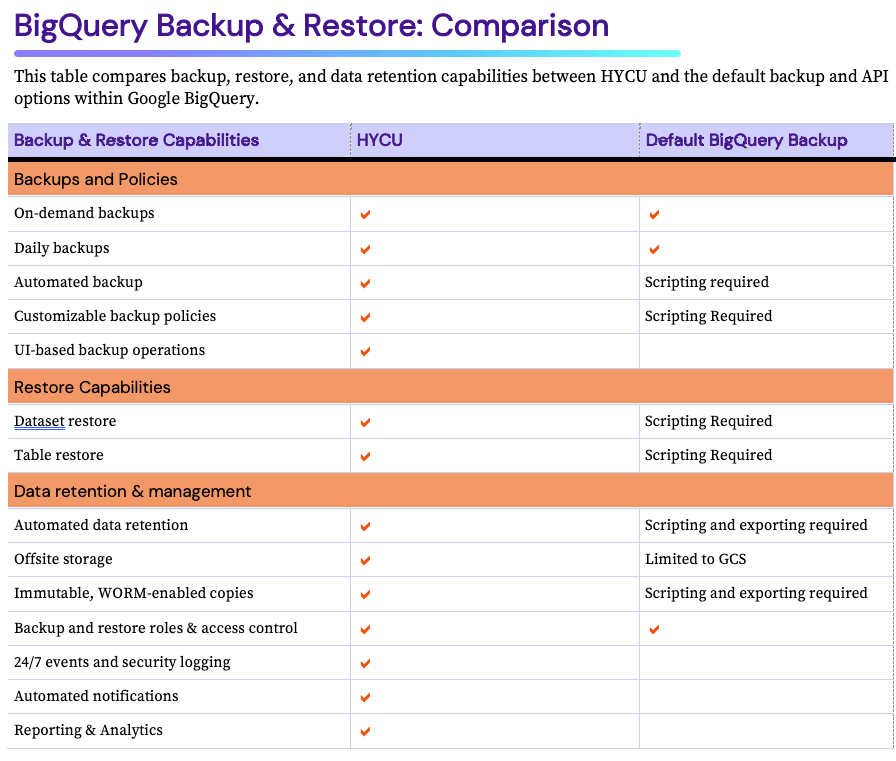
Using HYCU for Google BigQuery Backup
When it comes to protecting your data on Google BigQuery, HYCU offers a comprehensive and easy-to-use solution.
- In the event of data loss or system failure, HYCU enables instant restore functionality to return your tables and previous states. This way, there’s minimal downtime and business interruption.
- Another benefit and superpower of HYCU is its accurate and reliable recovery process for Google Cloud. HYCU ensures the restored data maintains its integrity and consistency, mirroring the state of the data at the time of the backup. This is particularly crucial for analytical or complex workloads on BigQuery, where data accuracy and consistency are paramount.
Restore tables and data sets in a few clicks

Automate all backup operations in 1-click

HYCU automates the backup of your BigQuery datasets, tables, and schemas, eliminating the need for manual intervention. This frees up your time and dramatically reduces the risk of human error (e.g., misuse of a mouse leading to accidental deletion) leading to data loss.
Furthermore, HYCU offers the ability to customize backup settings:
- Schedule backups for off-peak hours to minimize the impact on performance.
- Set retention policies for regulatory compliance.
- Choose backup storage locations for data sovereignty.
And all of these backups are encrypted during transit and at rest, ensuring the security of your data.
Compute-free, native Google Cloud Backups
HYCU is natively built to work with Google APIs, and customers do not have to use a script to perform configs for traditional backup operations.
In addition, you can configure HYCU to back up your BigQuery data to Google Cloud Storage (GCS) for long-term data retention. This flexibility ensures that your backed-up data can be readily utilized or migrated according to your specific use cases or requirements.
Beyond BigQuery: protect your Google Cloud infrastructure
HYCU provides automated backups and granular restore across Google Cloud Infrastructure, DBaaS, PaaS, and SaaS. In fact, HYCU boasts the most comprehensive coverage of Google Cloud infrastructure and services with complete support for:
- Google Cloud Engine (GCE)
- Google Cloud Storage
- Google CloudSQL
- Google BigQuery
- Google Kubernetes Engine (GKE)
- Google Cloud VMware Engine
- Google Workspace
- SAP HANA in Google Cloud
Protect multi-cloud infrastructure, PaaS, DBaaS, and SaaS
HYCU is not limited to backing up your BigQuery data; it also supports various data sources and workloads. This means whether you have other workloads in Google, other public clouds, on-premises data centers, or even SaaS, DBaaS, and PaaS applications - HYCU can back it up and restore it seamlessly.
On the flip side, specifically for BigQuery, HYCU provides comprehensive data protection. This ensures that all your BigQuery data, including individual tables and schema, can be restored.
💡 Related → Top 14 SaaS Backup Solutions & Tools for SaaS Data Protection
Subscribe and protect in a few clicks
One of HYCU’s standout features is its user-friendly interface and thorough documentation, which makes setting up and configuring your BigQuery backups effortless.
For instance, HYCU simplifies backup operations by automatically discovering all instances and workloads in your account, enabling you to assign pre-packaged policies in one click or create your own.
Notably, these policies are ‘set-and-forget’ — meaning, they run 24/7/365 without any manual operations or day-to-day management.
Enhanced Data Protection and Security
Apart from automatically inheriting Google Cloud IAM (Identity and Access Management) roles and permissions, HYCU also provides a Role-Based Access Control (RBAC) feature.
This feature allows you to define access rights and roles for backup and restore operations. This helps prevent unauthorized access and ensures your data backups are handled securely and professionally.
This integration ensures that backup and restore operations are only performed by authorized users.
Cost-Effective Pricing
HYCU offers flexible pricing options, ensuring businesses of all sizes benefit from its robust backup capabilities. The cost of using HYCU scales to your specific needs, such as the amount of data you need to back up, the frequency of backups, and the required retention period. This approach allows you to tailor the service to your requirements, ensuring you only pay for what you need.
One View of Your Google Estate with Protection Status
If your organization is like most, you may be using way more Google services along with other public cloud services and SaaS applications. This presents a massive challenge in tracking, let alone in making sure the data and configuration are protected and available for restore. With R-Graph, HYCU users can track all cloud infrastructure, services, PaaS, DBaaS, and SaaS in one single ‘treasure map’ view. You’ll be able to track which services are protected and compliant and which require protection.
💡 Related → Google Workspace (G Suite) Backup & Recovery Solution
Default BigQuery Backup Options and Configurations
To enable BigQuery Backup, you need administrator access with the following IAM roles to manage datasets:
- Copy a dataset (Beta):
- BigQuery Admin (roles/bigquery.admin) on the destination project
- BigQuery Data Viewer (roles/bigquery.dataViewer) on the source dataset
- BigQuery Data Editor (roles/bigquery.dataEditor) on the destination dataset
- Delete a dataset: BigQuery Data Owner (roles/bigquery.dataOwner) on the project
- Restore a deleted dataset: BigQuery Admin (roles/bigquery.admin) on the project
Once you have access, you can manage the backup configurations and options below.
Copy Dataset-level backups
A typical dataset in BigQuery is a top-level container that houses your tables and views. It’s also an effective way to organize and control access to your data. For example, separating raw data from processed data or data from different departments or projects.
On the flip side, configuring dataset-level backups involves creating and exporting a copy of your data to a specific location, e.g., a Cloud Storage bucket. This action ensures the availability and integrity of your data, even in the event of accidental deletion or modification.
Methods of configuring dataset-level backups
There are two methods of configuring dataset-level backups; BigQuery API and SQL commands.
Using BigQuery API
The BigQuery API enables you to use the BigQuery Data Transfer Service to schedule automated data transfers from BigQuery for a Cloud Storage bucket.
- Since backups will be stored in the Google Cloud Storage bucket, create a new bucket under the “Storage” section in the Cloud Console.
- Go to the API library and enable the BigQuery Data Transfer Service API and Cloud Storage API.
- Choose a programming language and install the corresponding client library for the BigQuery API. Read the documentation here.
- Install the Google Cloud SDK. This provides the necessary command-line tool to interact with APIs and other Google Cloud services.
- Authenticate the SDK with your Google Cloud Account using the commands from the gCLI. This ensures the SDK can access and perform operations on your behalf.
- If you don’t already have one, create a new dataset.
- Define the configuration. Specify dataset, project, table IDs, and Cloud Storage Bucket.
- Export the data from your BigQuery tables to a Cloud Storage bucket by making a request to the API.
Once the process is confirmed, ensure that your BigQuery dataset and Cloud Storage are in the exact location to avoid potential issues.
💡Note → This BigQuery backup option is only a copy of the existing data and not an incremental.
Recommended → Learn more about Google Cloud APIs
Using SQL commands
SQL commands in BigQuery provide another option to manage and interact with datasets. In the context of ‘backing up data, this isn’t entirely possible —the same is the case for all BigQuery backup options. Instead, it’s creating a new table with existing data.
Recommended → Read Google’s documentation on creating datasets using SQL commands.
💡Note: This is not precisely a ‘backup’ solution; instead, you’re creating datasets in another location.
Aside from setting up these backup configurations in BigQuery, there are some key parameters you need to consider:
- Backup Frequency. This is entirely dependent on the frequency of your data changes. If your data changes rapidly, you may need daily or hourly backups. If that’s not the case, you can set it to monthly or weekly.
- Retention Policies. This isn’t the same across the board and can be defined based on your company’s requirements as long as it complies with the data laws governing your industry.
- Schema Preservation. This critical aspect of the configuration ensures your data's schema (or structure) remains intact. This means all data types, names, tables, and other relevant information are accurate even during replication.
Table-level snapshots
The table-level backup in BigQuery enables you to select individual tables within a dataset for backup. This is particularly useful in scenarios where only some tables in the dataset require backing up.
Creating snapshots for individual tables.
There are two standard methods for creating snapshots for individual tables;
- You can use the ‘bq extract’ command via the command-line tool, OR
- You can use the BigQuery API to make a request.
Here’s an example:
bq extract 'my_dataset.my_table' gs://my_bucket/my_table_backup
Where:
- ‘my_dataset.my_table’is the table you want to backup — and,
- ‘gs://my_bucket/my_table_backup’is the GCS location where the backup will be stored.
Both methods will export the table data as files in your chosen format to the Google Cloud Storage (GCS) bucket, making it easier to import and restore the table if needed.
The GCS is a preferable option for storing your BigQuery table backups due to its security, reliability, and cost-effectiveness.
Exporting your BigQuery table backups in different formats.
You can export your table data in the following formats:
- JSON (Javascript Object Notation). This is a flexible and human-readable format, so it’s easier to understand and work with. However, it can be larger (in size) and slower than other formats.
- CSV (Comma-Separated Values). This is a simple and widely supported format for most table data representation scenarios. However, it doesn’t accurately present complex data structures.
- Avro is a row-oriented and data serialization framework. Its compact binary format makes it ideal for handling large datasets— especially where the table schema changes over time. Additionally, you can compress files stored in Avro format, reducing storage and faster backup/restore time.
- Parquet (Apache Parquet) is a column-oriented data storage format. It can also handle large datasets and offers excellent compression capabilities. However, it may have some limitations regarding frequent table updates.
Handling partitioned BigQuery tables and incremental backups
Partitioning tables in BigQuery is an approach to managing and organizing large datasets.
Ideally, you should perform a backup based on the existing partition strategy.
For this, you can either:
- backup the entire table, including all partitions, OR
- or backup specific partitions.
However, exporting only modified or newly added partitions is more storage-efficient if you're dealing with incremental backups.
For example, if your table is partitioned by date, you can only extract today’s partition.
Limitations of table-level snapshots
- A table snapshot must be in the same region, and under the same organization, as its base table.
- Table snapshots are read-only. You can't update the data in a table snapshot unless you create a standard table from the snapshot and then update the data. You can only update a table snapshot's metadata; for example, its description, expiration date, and access policy.
- You can only take a snapshot of a table's data as it was seven days ago or more recently due to the seven-day limit for time travel.
- You can't take a snapshot of a view or a materialized view.
- You can't take a snapshot of an external table.
- You can't overwrite an existing table or table snapshot when you create a table snapshot.
- If you snapshot a table that has data in write-optimized storage (streaming buffer), the data in the write-optimized storage is not included in the table snapshot.
- If you snapshot a table that has data in time travel, the data in time travel is not included in the table snapshot.
- If you snapshot a partitioned table that has a partition expiration set, the partition expiration information isn't retained in the snapshot. The ‘snapshotted’ table uses the destination dataset's default partition expiration instead. To retain the partition expiration information, copy the table instead.
- You can't copy a table snapshot.
Snapshot-based backups
A snapshot in BigQuery is a point-in-time copy of the data of a table (called the base table). This means it captures the state of the table and its data at a specific time, allowing you to restore from that specific point if needed.
Simply put, it’s taking a picture of your data. And it can be valuable for instances such as compliance, auditing or trend analysis, where it provides a consistent view of the data as it existed at a point in time.
💡Note → Table snapshots are ‘read-only’, but you can create/restore a standard table from a snapshot and then modify it.
Creating and managing snapshots for point-in-time recovery
You can create a snapshot of a table using the following options:
- Google Cloud Console
- SQL statement
- The
bq cp --snapshotcommand - jobs.insert API
For example, if you’re using the Google Cloud Console, follow these steps:
- Go to the Cloud Console, and navigate to the BigQuery page.
- Find the ‘Explorer’ pane, and expand the project and dataset nodes of the table you want to snapshot.
- Click the name of the table, and click on ‘SNAPSHOT.’

- Next, a ‘Create table snapshot’ would appear. Enter the Project, Table and Dataset information for the new table snapshot.
- Set your Expiration time.
- Click Save.
Once you create this snapshot, it’s detached from the original table. This means any changes to the table won't affect the snapshot’s data in the new table.
Recommended → Learn more about creating table snapshots using other options.
Benefits of snapshot-based backups
- Data versioning. This allows you to access data as it appeared at specific points in time. With this, you can trace back changes or restore data to its original state if necessary.
- Historical analysis. You can compare different snapshots to track data changes over time. This can help you gain insights into trends, improving your decision-making process.
- Data retention. Some industries and organizations have strict data retention policies to comply with regulatory requirements. Snapshot-based backups enable you to retain data for a specific duration as mandated by regulations.
Utilizing BigQuery time travel feature for data restoration
BigQuery offers a feature called ‘time travel’, allowing you to access your table's historical versions in the past seven days.
With the time travel feature, you can restore or preserve a table’s data from a specific time, undoing any changes done after that chosen timestamp.
Snapshot-based backups and the time travel feature significantly bolster your data protection strategy in BigQuery.
Note that “time travel” is not a guaranteed recovery solution in the event of operation failure, cyber attack, or natural disasters.
Here’s why:
- The time window to recover data is limited to seven days. If there’s an issue that goes undetected within that time frame, the data can not be recovered.
- Time travel does not offer the option to duplicate or back up your data. All it does is merely allow you to go back to the previous states of your data.
Due to this, it becomes critical to employ other backup measures like regular data exports to Google Cloud Storage and data replication to ensure comprehensive data safety.
Implementing BigQuery Backup Solutions
Using Python and GitHub
With its easy-to-use and vast library support, Python makes it easier to interact with BigQuery and automate the entire backup process.
Now, using Python with GitHub, a leading platform for hosting and version-controlling code, you can manage your scripts, track changes — and even collaborate with others.
To make this work, you need to leverage existing Python libraries and repositories to streamline your development process:
- google-cloud-bigquery. This official Python library is from Google Cloud, and it provides functionalities such as managing datasets, scheduling, and executing queries.
Here’s an example of using Python to perform a query
from google.cloud import bigquery
client = bigquery.Client()
# Perform a query.
QUERY = (
'SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` '
'WHERE state = "TX" '
'LIMIT 100')
query_job = client.query(QUERY) # API request
rows = query_job.result() # Waits for query to finish
for row in rows:
print(row.name)- google-cloud-storage. This library makes it convenient to automate storing your backups in Google Cloud.
- pandas-gbq. This library bridges the gap between BigQuery and Pandas. It simplifies retrieving results from BigQuery tables using SQL-like queries.
Examples of what you can do with the pandas-gbq library:
Performing a query:
import pandas_gbqresult_dataframe = pandas_gbq.read_gbq("SELECT column FROM dataset.table WHERE value = 'something'")
Uploading a dataframe:
import pandas_gbqpandas_gbq.to_gbq(dataframe, "dataset.table")
In addition, adhering to some standard best practices is crucial when using Python and GitHub to create BigQuery backups.
- Monitor your backup jobs. Implement error handling and logging into your scripts to trigger an alert system that notifies you of potential issues with the backup process.
- Modularize your Python scripts. Modularization is simply a way of organizing programs as they become more complicated. In this case, split your backup-related functions into reusable models, making them easier to manage and maintain as they grow.
- Use configuration files. Also known as ‘config files,’ these are used to store key-value pairs of a Python code. For example, when running BigQuery backups, you can use a configuration file to store project IDs, dataset names, and backup locations. This allows for easy modification without tampering with the code.
Using Command Line and Google Cloud SDK
The Command Line (or the gCLI) is a set of tools used to manage applications and resources hosted on the Google Cloud. These tools include gcloud, gsutil, and bq command-line tools. For example, you can schedule and automate all backup-related tasks with the command line.
On the other hand, the Google Cloud SDK makes it easier to develop and interact with the Google Cloud API using your preferred programming language.
Combine both, and you can conveniently manage your BigQuery backups.
How to set up your Google Cloud SDK.
- Head to Cloud SDK - Libraries and Command Line Tools | Google Cloud.
- Download the installation package of your respective machine (Windows, macOS, Ubuntu, and Linux) and follow the instructions on the page.
- Install the Google Cloud SDK using the ‘./google-cloud-sdk/install.sh’ and follow the necessary prompts.
- Authenticate your account to enable BigQuery resources using the ‘gcloud auth login’ command line.
Now that your Google Cloud SDK is set up, the next is to use the command line to perform various backup functions.
Creating backups
To create a BigQuery backup using the ‘[bq cp]’ command line is simply copying the table from one location to another. The locations could be across different projects, different datasets, or even within the same datasets.
bq cp [project_id]:[dataset].[table] [project_id]:[backup_dataset].[backup_table]
Where your;
- ‘[project_id]’ is your Google Cloud id.
- ‘[dataset]’ contains the table you want to back up.
- ‘[table]’ contains the name of the table you want to backup.
- ‘[backup_dataset]’ is the dataset where you want to store the backup.
- ‘[backup_table]’ is the name of the backup table.
Export data
You use the ‘[bq extract]’ command line to export data from BigQuery to Google Cloud Storage or external storage systems. This command line also enables data export in JSON, CSV, Avro, and Parquet.
bq extract --destination_format=[format] [project_id]:[dataset].[table] gs://[bucket]/[path]
Here, replace;
- ‘[format]’ with your desired export format.
- ‘[bucket]’ with the name of your Google Cloud Storage bucket.
- ‘[path]’ with the path you want to store the exported data.
For example:
bq extract --destination_format CSV 'mydataset.mytable' gs://mybucket/mydata.csv
Manage backups
To manage your BigQuery backups, you use the ‘[bq ls]’ command to list all the backups [or table] in a specific dataset — or ‘[bq rm]’ to delete a table.
bq ls mydatasetbq rm 'mydataset.mytable'
Limitations of BigQuery Backup Options
Limited point-in-time recovery option
Suppose you have a critical dataset in BigQuery that undergoes frequent updates and transformations. One day, the dataset becomes inaccurate due to a data corruption issue.
Since BigQuery doesn't offer point-in-time recovery, you cannot easily restore the dataset to a state before the corruption occurred. Without automated backups, you might need to rely on manual exports or snapshots that you've taken previously, which could be time-consuming and potentially outdated.
Complex import and export process
Say you have a large dataset in BigQuery and want to create a backup in an external storage system, such as Google Cloud Storage (GCS); while BigQuery allows exporting data in formats like Avro, Parquet, or CSV, exporting large datasets can be complex and resource-intensive.
For example, exporting several terabytes of data to GCS might require considerable time and network resources, leading to additional costs and potential disruptions to ongoing operations.
Poor backup retention policy
By default, BigQuery retains deleted tables or datasets in the “Trash” for 30 days before permanent deletion. While this provides some level of protection against accidental deletions, you can't extend or customize this retention period.
Resource intensive scripting and configuration
Managing scripts and custom configurations can be complex, especially as the environment scales. Managing scripts can be daunting and time-intensive for a service like BigQuery, let alone if you’re responsible for managing multiple cloud services.
BigQuery Backup & Recovery: The Bottom Line
Google BigQuery is undoubtedly a powerful tool for data-driven organizations. Its lightning-fast SQL queries, built-in machine learning capabilities, and scalable infrastructure make it a reliable solution — especially for processing large amounts of data. However, the valuable scheme, datasets, and tables residing in BigQuery must be protected to mitigate the risks of data loss or system failures. This is where HYCU comes to save the day.
With HYCU Protégé, you get 1-click backups and granular restore for your BigQuery data. This automated “set and forget” backup runs 24/7/365, offering you complete peace of mind that your data BigQuery will be available when needed.
Need a cloud-native backup & restore for Google BigQuery?

Andy Fernandez is the Director of Product Management at HYCU, an Atlassian Ventures company. Andy's entire career has been focused on data protection and disaster recovery for critical applications. Previously holding product and GTM positions at Zerto and Veeam, Andy’s focus now is ensuring organizations protect critical SaaS and Cloud applications across ITSM and DevOps. When not working on data protection, Andy loves attending live gigs, finding the local foodie spots, and going to the beach.